Shawn Introduction
Software for WSNs must be thoroughly tested prior to real-world deployments since sensor nodes do not offer convenient debugging interfaces and are typically inaccessible after deployment. Furthermore, successfully designing algorithms and protocols for WSNs requires a deep understanding of these complex distributed networks. To achieve these goals, three different approaches are commonly used:
- Analytical methods
- Real-world experiments
- Computer simulations
Analytical methods are typically not well-suited to support the development of complete WSN applications. Despite their expressiveness and generality, it is difficult to grasp all details of such complex, distributed applications in a purely formal manner.
Real-world experiments are an attractive option as they are a convincing means to demonstrate that an application is able to accomplish a specific task in practice – if the technology is already available. However, due to the unpredictable environmental influences it is hard to reproduce results or to isolate sources of errors. Furthermore, real-world deployments are laborious and involve management tasks that are not directly related to the problem. For this reason, they are typically limited to a few dozens of devices, while future scenarios anticipate networks of several thousands to millions of nodes. Computer simulations are a promising means to tackle the task of algorithm and protocol engineering for WSNs. A number of simulation tools are available. They reproduce real-world effects inside a simulation environment including radio propagation properties and environmental influences. This mitigates required efforts for real-world deployments and may therefore help to increase their size. However, the high level of detail provided by these tools obfuscates and misses another, much more crucial issue: The large number of factors that influence the behavior of the whole network renders it nearly impossible to isolate a specific parameter of interest.
For example, consider the development of a novel routing protocol. In the case of a very low throughput, the cause of the problem is not clear at first sight, as the sources for the error are manifold: the MAC layer might be faulty; cross-traffic from other senders could limit the available bandwidth; radio propagation properties might have changed or the routing protocol’s algorithm is not yet optimal. Therefore, it is not only sufficient to simulate a high number of nodes with a high level of detail. Instead, developers require the ability to focus on the actual research problem. When designing algorithms and protocols for WSN it is important to understand the underlying structure of the network – a task that is often one level above the technical details of individual nodes and low-level effects.
There is certainly some influence of communication characteristics, e.g., because they affect transmission times, communication paths and packet loss. From the algorithm’s point of view, there is no difference between a complete simulation of the physical environment (or low-level networking protocols) and the alternative approach of using well-chosen random distributions on message delay and loss. Thus, using a detailed simulation may lead to the situation where the simulator spends much processing time on producing results that are of no interest at all.
By contrast, they actually hinder productive research on the algorithm. To improve this situation, we propose a novel simulation tool called Shawn. The central idea of Shawn is to replace low-level effects with abstract and exchangeable models so that simulations can be used for huge networks in reasonable time while keeping the focus on the actual research problem.
For a discussion of [related work](Related Work), please look here [here](Related Work).
Shawn differs in various ways from the above-mentioned simulation tools, while the most notable difference is its focus. It does not compete with these simulators in the area of network stack simulation. Instead, Shawn emerged from an algorithmic background. Its primary design goals are:
- Simulate the effect caused by a phenomenon, not the phenomenon itself.
- Scalability and support for extremely large networks.
- Free choice of the implementation model.
As discussed above, most simulation tools perform a complete simulation of the MAC layer including radio propagation properties such as attenuation, collision, fading and multi-path propagation. A central design guideline of Shawn is to simulate the effect caused by a phenomenon, and not the phenomenon itself. Shawn therefore only models the effects of a MAC layer for the application (e.g., packet loss, corruption and delay).
This has several implications on the simulations performed with Shawn. On the one hand, they are more predictable and there is a performance gain since such a model can be implemented very efficiently. On the other hand, this means that Shawn is unable to provide the same detail level that, for example, Ns-2 provides with regard to physical layer or packet level phenomena. However, if the model is chosen well, the effects for the application are virtually the same. Imagine two implementations of a MAC layer: One abstract implementation that yields an increased packet loss on high local traffic and one that calculates interference for single packets using radio propagation models. Both will produce similar effects on the application layer.
It must be mentioned though that the interpretation of obtained results must take the properties of the individual models into account. If, for instance, a simplified communication model is used to benchmark the results of a localization algorithm, the quality of the obtained solution remains unaffected. However, the actual running time of the algorithm is not representative for real-world environments since no delay or loss occurs.
One central goal of Shawn is to support orders of magnitudes higher numbers of nodes than the currently existing simulators. By simplifying the structure of several low-level parameters, their time-consuming computation can be replaced by fast substitutes as long as the interest in the large-scale behavior of the system focuses on unaffected properties. A direct benefit of this paradigm is that Shawn can simulate vast networks.
To enable a fast simulation of these scenarios, Shawn can be custom-tailored to the problem at hand by selecting appropriate configuration options. This enables developers to optimize the performance of Shawn specifically for each single scenario. For example, a scenario without any mobility can be treated differently than a scenario where sensor nodes are moving.
Shawn supports a multi-stage development cycle where developers can freely choose the implementation model as depicted in the following figure.

Using Shawn, they are not limited to the implementation of distributed protocols. The rationale behind this approach is that – given a first idea for a novel algorithm – the next natural step is not the design of a fully distributed protocol. In fact, it is more likely to perform a structural analysis of the problem at hand. To get a better understanding of the problem in this phase, it may be helpful to look at some exemplary networks to analyze their structure and the underlying graph representation.
The next step may be to implement a centralized version of the algorithm in order to achieve a rapid prototype version. A centralized algorithm has full access to all nodes and has a global, flat view of the network. This provides a simple means to obtain results and get a first impression of the overall performance of the algorithm in question. The results emerging from this process can provide optimization feedback for the algorithm design.
Once a satisfactory state of the centralized version has been achieved, the feasibility of its distributed implementation can be investigated. Since the aim of this step is to prove that the algorithm can be transformed to a distributed implementation, a simplified communication model between individual sensor nodes can be utilized. This allows for an efficient and fast implementation, yet with meaningful results.
This simplified version can be transformed gradually into a protocol that actually exchanges network messages containing protocol payload. With the protocol and data structures in place, the performance of the distributed implementation can be evaluated. Interesting questions that can be explored are for instance the number of messages, energy consumption, run-time, resilience to message loss and effects of the environment. This development cycle helps the developer to start from an initial idea and gradually leads to a fully distributed protocol. However, each step of the cycle is optional and it is up to the developer to pick only the necessary ones.
Shawn's architecture that is shown in the figure on the right comprises three major parts: 
- Models
- Sequencer
- Simulation Environment
Every aspect of Shawn is influenced by one or more Models, which are the key to its flexibility and scalability. The Sequencer is the central coordinating unit in Shawn as it configures the simulation, executes tasks sequentially and controls the simulation. The Simulation Environment is the home for the virtual world in which the simulated sensor nodes reside. In the following, the functionality of these core components is described in detail.
Shawn distinguishes between models and their respective implementations. A model is the interface used by Shawn to control the simulation without any knowledge on how a specific implementation may look like. Shawn maintains a repository of model implementations that can be used to compose simulation setups by selecting the desired behaviors. The implementation of a model may be simplified and fast, or it could provide close approximations to reality. This enables the user to select the most appropriate implementation of each model to fine-tune Shawn’s behavior for a particular simulation task. As depicted in Shawn's architecture above, three models form the foundation of Shawn:
- Communication Model
- Edge Model
- Transmission Model
In the following, these models and their already included implementations are explained in detail. Other models of minor importance are briefly introduced at the end of this section.
Whenever a simulated sensor node in Shawn transmits a message, the potential receivers of this message must be identified by the simulator. Please note that this does not determine the properties of individual transmissions but defines whether two nodes can communicate as a matter of principle. This question is answered by implementations of the [Communication Model](Communication Model). The following code presents the C++ interface of the Communication Model. A single method is invoked to determine whether the node b is in reach of the node a.
class CommunicationModel
{
...
bool can_communicate_uni (Node& a, Node& b);
...
};
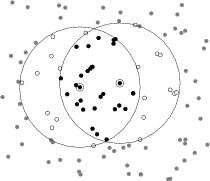
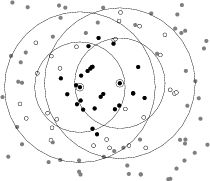
By implementing this interface with user-defined code, arbitrary communication patterns can be realized. Shawn ships with a set of different [Communication Model](Communication Model) implementations that are shown in the following figure.
{| align="center"
|  |
|  |
|  |}
|}
Three of these five implementations resemble communication patterns that are often used in WSN research. The figures above shows examples of how these models work. In the figure, the shared neighbors (filled black circles) of two nodes n1 and n2 (filled black circle with an extra black ring) are highlighted. The [Unit Disk Graph](Unit Disk Graph) (UDG) radio model is based on the observation that the signal strength fades with the square of the distance from the sender. Given a minimum signal strength required for reception, two nodes can communicate bidirectional if the Euclidean distance d between the nodes is less than rmax. Regardless of its substantial abstractions from the real world, the model is widely utilized in WSN research because of its simplicity.
The [Quasi-Unit Disk Graph](Quasi-Unit Disk Graph) (Q-UDG) radio model is a variant of the model introduced in Barriere, L., Fraigniaud, P., and Narayanan, L. Robust positionbased routing in wireless ad hoc networks with unstable transmission ranges. In DIALM ’01 (New York, NY, USA, 2001), ACM Press, pp. 19–27. Q-UDG radio model.. It defines two new distances r1 and r2 with r1 < r2. For 0 < d < r1 and d > r2, the behavior is equivalent to the UDG Model. For r_1 \leq d \leq r_2, the packet reception probability decreases linearly from 1 to 0. It therefore honors the fact that the probability of a successful reception diminishes with increasing distance. The second figure shows an example with r_1=0.75r_{max} and r_2=1.25r_{max}.
Based on real-world experiments, the [Radio Irregularity Model](Radio Irregularity Model) (RIM) Zhou, G., He, T., Krishnamurthy, S., and Stankovic, J. A. Impact of radio irregularity on wireless sensor networks. In MobiSys ’04: Proceedings of the 2nd international conference on Mobile systems, applications, and services (2004), pp. 125–138. Zhou, G., He, T., Krishnamurthy, S., and Stankovic, J. A. Models and solutions for radio irregularity in wireless sensor networks. ACM Trans. Sen. Netw. 2, 2 (2006), 221–262. , proposes an angle dependant range between a minimum and a maximum communication range (r_{min} and r_{max}). A factor determines the maximum change in transmission range per degree and thus controls the irregularity of the shape. In contrast to UDG and Q-UDG, the RIM model also yields unidirectional links.
In addition to the real-world models, the [Permanent Link](Permanent Link) model allows the specification of static links to pre-define communication relations such as wired connections to gateway nodes. The [Chained Communication Model](Chained Communication Model) supports combining multiple communication models to a single communication model. For instance, while most of the sensor nodes in a network could use the [Unit Disk Graph](Unit Disk Graph) model, some gateway nodes have wired connections that are modeled by a [Permanent Link](Permanent Link) model.
The Edge Model provides a graph representation of the network. The simulated nodes are the vertices of the graph and an edge between two nodes is added whenever the Communication Model returns true. To assemble this graph representation, the Edge Model repeatedly queries the Communication Model. It is therefore possible to access the direct neighbors of a node, the neighbors of the neighbors, and so on. This is used by Shawn to determine the potential recipients of a message by iterating over the neighbors of the sending node. Simple centralized algorithms that need information on the communication graph can be implemented very efficiently as in contrast to other simulation tools, no messages must be exchanged that serve as probes for neighboring nodes.
The listing below depicts the C++ interface that must be extended by implementations of the Edge Model. In essence, two methods provide the ability to iterate over the neighbors of a node for a specific communication direction. The communication direction parameter defines how the property “neighbor” is interpreted and can be one of the following: in, out, bidirectional or any. If not specified, the communication direction defaults to “bidi”.
class EdgeModel
{
...
adjacency_iterator begin_adjacent_nodes (Node &,
CommunicationDirection d = bidi);
adjacency_iterator end_adjacent_nodes (Node &);
...
};
The communication direction property is defined as follows: u and v are neighbors if for the communication direction
- “in” holds: can communicate uni(v, u),
- “out” holds: can communicate uni(u, v),
- “bidi” holds: can communicate uni(u, v) ^ can communicate uni(v, u),
- “any” holds: can communicate uni(u, v) v can communicate uni(v, u).
Depending on the application’s requirements and its properties, different storage models for these graphs are needed. For instance, mobile scenarios require different storage models than static scenarios. In addition, simulations of relatively small networks may allow storing the complete neighborhood of each node in memory. Conversely, huge networks will impose impractical demands for memory and hence supplementary edge models trade memory for runtime, e.g., by recalculating the neighborhood on each request or by caching a certain amount of neighborhoods. Accordingly, Shawn provides different EdgeModel implementations as shown in the figure below.

The [Lazy Edge Model](Lazy Edge Model) is intended for simulations with only a small amount of nodes, hardly any communication or high node mobility. It does not store any information but recalculates the graph on the fly by querying the current [Communication Model](Communication Model). The [Grid Edge Model](Grid Edge Model) uses a two-dimensional grid for arranging nodes according to their geometric position. Therefore, the search for neighboring nodes is restricted to nearby ones, thus effectively improving the lookup speed while still fully supporting mobility. The [List Edge Model](List Edge Model) stores the complete graph of the network in memory. This allows for a faster iteration over the neighboring nodes at the cost of a time-consuming initial construction and non-negligible memory demands. Since the list is only built once at the beginning of the simulation, this edge model does not support node mobility but only static scenarios. The [Fast List Edge Model](Fast List Edge Model) combines the functionality of the Grid and List edge models into a single model implementation. Internally, it uses a Grid edge model for the initial construction of a contained [List Edge Model](List Edge Model). As a result, it provides the features of the List edge model plus a fast construction at the cost of a higher initial memory footprint.
Whenever a node transmits a message, the behavior of the transmission channel may be completely different than for any other message transmitted earlier. For instance, cross traffic from other nodes may block the wireless channel or interference may degrade the channel’s quality. To model these transient characteristics inside Shawn, the [Transmission Model](Transmission Model) determines the properties of an individual message transmission. It can arbitrarily delay, drop or alter messages.
This means that a message may not reach its destination even if the [Communication Model](Communication Model) states that two nodes can communicate as a matter of principle and the Edge Model lists these two nodes as neighbors. The code below shows the C++ interface for transmission model implementations in Shawn. The send message()-method accepts a MessageInfo data structure containing the message itself, the time of transmission and the position of the sender.
class TransmissionModel
{
struct MessageInfo
{
Node* src_;
Vec src_pos_;
double time_;
MessageHandle msg_;
};
...
void send_message (MessageInfo&);
...
};
Again, the choice of an implementation strongly depends on the simulation goal. In case that the runtime of an algorithm is not of interest but only its quality, a simple transmission model without delay, loss or message corruption is sufficient. Models that are more sophisticated could take contention, transmission time and errors into account at the cost of performance.

Besides these core models that shape the fundamental behavior of Shawn, a number of more specialized models provide data for the simulations. Currently, Shawn contains models for [random variables](Random Variable), [distance estimations](Node Distance Estimate) and [mobility](Node Movement).
Random variables are often needed in simulations to mimic uncertainty and randomness present in the real world. The [Random Variable Model](Random Variable Model) introduces a layer of abstraction between the actual sources of random data and the application. As a result, algorithms can be tested with different underlying random variables without changes to the implementation.
Sensor nodes often need distance estimations to other nodes to acquire context information such as their position. In Shawn, the [Node Distance Estimate](Node Distance Estimate) model provides these distance estimations, e.g. to support the evaluation of localization algorithms.
Modeling arbitrary mobility is supported by so-called [Node Movements](Node Movement). Implementations of this model provide the current position of a node when queried, e.g. by the communication model or an application. In order to allow an observation of the movement of nodes, listeners can register with the movements for location updates. Whenever a node is about to leave a previously supplied area given by a bounding box, it notifies the listener and obtains a new bounding box. This mechanism is used e.g. by the [Grid Edge Model](Grid Edge Model) to adapt its internal status.
The sequencer is the control center of the simulation: it prepares the world in which the simulated nodes live, instantiates and parameterizes the implementations of the models as designated by the configuration input and controls the simulation. It consists of
- Simulation Tasks, the
- Simulation Controller and the
- Event Scheduler.
Simulation Tasks are pieces of code that are invoked from the configuration of the simulation supplied by the user. They are not directly related to the simulated application but they have access to the whole simulation environment and are thus able to perform a wide range of tasks. Example uses are managing simulations, gathering data from individual nodes or running centralized algorithms.
Shawn exclusively uses [tasks](Simulation Task) to expose its internal features to the user. A variety of tasks is included in Shawn that supports the creation and parameterization of new simulation worlds, nodes, routing protocols, random variables, etc. Even the actual simulation is triggered using a task and the user can specify the amount of time that should be simulated upon the execution of this simulation task.
class SimulationTask
{
...
void run (SimulationController&);
string name ();
string description ();
...
};
Simulation Tasks are configured and invoked by the [Simulation Controller](Simulation Controller) as discussed later on. They are identified and invoked using a unique name and parameters are passed as simple (name, value)-pairs. The listing above presents the C++ interface that a simulation task implementation must extend: One method that returns the unique identifying name, one that returns a human readable description and one that performs the actual task.
See also:
- [Simulation Task](Simulation Task)
- [Pre Step Task](Pre Step Task)
- [Post Step Task](Post Step Task)
The Simulation Controller acts as the central repository for all available model implementations and runs the simulation by transforming the configuration input into parameterized invocations of Simulation Tasks. In doing so, it mediates between Shawn’s simulation kernel and the user. In line with most other components of Shawn, the Simulation Controller can be customized by a developer to realize an arbitrary control over the simulation. The default implementation reads the configuration commands from a text file or the standard input stream. The following code snipped shows how these commands are structured.
global_name1=global_value1
task_name name1=value1 name2=value2
Two different line formats can occur: one that defines global variables and one that invokes and parameterizes Simulation Tasks. Line 1 shows how a global (name, value)-pair is specified which is valid from the point of its definition until the simulation run completes. Line 3 shows how a task is invoked by specifying its name (as returned by the task’s name()-method) separated with a trailing blank character. Following the tasks name, (name, value)-pairs may occur that are valid for the invocation of the task (local values temporarily overwrite global ones if their names are identical).
If a simulation task with this name is found, its run()-method is invoked and the current set of (name, value)-pairs is passed. Note that tasks are instantiated when Shawn starts and using the same task-name again results in invoking the run()-method on the same instance as for the first call. This can be used to collect data continuously and to evaluate it at a later point in time.
A second implementation (called JShawn) allows the use of Java-language scripts to steer the simulation. While providing the same functionality, it allows more complex constructs and evaluations already in the configuration file.
Shawn uses a discrete event scheduler to model time. The [Event Scheduler](Event Scheduler) is Shawn’s timekeeping instance. Objects that need the notion of time can register with the Event Scheduler to be notified at an arbitrary point in time. The simulation always skips to the next event time and notifies the registered [[EventHandler|handlers]. This process continues until all nodes signal either that they have powered down or until the maximum configured time has elapsed.
This has some performance advantages compared with traditional approaches that use fixed time intervals (such as a clock-tick every 1ms): First, handlers are notified only at the precise time that they have requested avoiding unnecessary calls to idle or waiting nodes that have no demand for processing. Second, users are not bound to some artificial granularity but an event may occur at the full precision that is offered by floating-point numbers. The figure below sketches how the Event Scheduler allows simulations to utilize this timing mechanism by using one of the several interaction possibilities.

Shawn logically arranges simulations into rounds (r = 0, 1, 2, . . .). The user may register Simulation Tasks as pre-step and post-step tasks that are executed immediately before (using [pre-step tasks](Pre Step Task)) and after (using [post-step tasks](Post Step Task)) each of these rounds. This is useful to extract information from the simulation without the need to intermingle simulation code with code that analyzes the performance of the simulated algorithm.
At the beginning of each round, a node’s work()-method is invoked. Applications can choose to use this method for an eased implementation when precise timing is not required. Apart from these fixed points in time, the nodes or other elements of the simulation may register an event at any point in time. Using these three distinct possibilities offers applications the required flexibility to integrate timing aspects into the simulation without degrading the overall performance.
The simulation environment is the home of the virtual world in which the simulation objects reside. As shown in Figure 4.3, the simulated Nodes reside in a single World instance. The Nodes themselves serve as a container for so-called Processors.
Developers using Shawn implement their application logic as instances of these Processors. By decoupling the application inside a Processor from the Node, multiple applications can easily be combined in a single simulation run without changing their implementations. For instance, one processor could implement an application specific protocol while another processor gathers statistics data.
The listing below shows an excerpt of the Processor’s API. After a processor has been instantiated, its boot()-method is invoked. A Processor can transmit messages by a call to send() and whenever a message for the Node is received, it dispatches this message to all its Processors by calling process message(). As mentioned above, the Processor’s work()-method is invoked whenever the Event Scheduler starts a new simulation round.
class Processor
...
void boot( );
bool process_message( MessageHandle& );
void work( );
Node& owner( );
void send( MessageHandle& );
...
};
A Node offers a number of services to the Processors that ease the implementation of algorithms and simplify the overall simulation task. As mentioned above, the Edge Model can be used to identify the neighbors of the current node. Unlike other simulators, Shawn does not restrict the user to a message-driven programming model but also allows "shortcuts", i.e., to execute method calls directly on other nodes. This is beneficial when implementing a centralized version of an algorithm or to get things done fast that are only a pre-condition for the current simulation, but not in the focus of the research.
It is often the case that an algorithm requires input that is produced by multiple (potentially very complex) other algorithms. To avoid waiting for the same results of these previous steps repeatedly in every simulation run, Shawn offers the ability to attach type-safe information to Nodes, the World and the Simulation Environment. Two Simulation Tasks (load world and save world) provide the ability to load Tags from and to save Tags to XML documents. Currently, three different Tag types exist: Simple Tags, Group Tags and Map Tags. Simple Tags contain a value of a certain type (e.g., string, int or Boolean), Group Tags contain other Tags and Map Tags contain pairs of values of a certain type. Figure 4.15(a) shows such an XML document that contains these different Tag types and Figure 4.15(b) shows how a Processor would access the Boolean Tag called base station.
<scenario>
<snapshot id="0">
<node id="runner12">
<location x="135.0" y="5.0" z="0.0"/>
<!−− Simple Boolean Tag −−>
<tag type="bool" name="base station" value="false"/>
<!−− Tag group containing other Tags −−>
<tag type="group" name="marathonnet">
<!−− Map Tag that maps one floating−point value to another −−>
<tag type="map−double−double" name="split times">
<entry index="0" value="0"/>
<entry index="21097.5" value="3801.0"/>
<entry index="42195" value="7658.0"/>
</tag>
</tag>
</node>
</snapshot>
</scenario>
//Find the Tag
ConstTagHandle th = owner ().find_tag("base station") ;
//Cast to the expected type (error checking omitted)
const BoolTag* bt = dynamic cast<const BoolTag*>( th.get() ) ;
//Retrieve the Tag’s value
bool is_basestation = bt−>value ( ) ;
A benefit of this concept is that it allows decoupling state variables from member variables in the user’s simulation code. By this means, parts of a potentially complicated protocol can be replaced without code modification because the internal state is stored in tags and not in member variables of a special implementation.
To model sensors and their corresponding sensor values, a generic framework called Readings and Sensors is provided. Readings deliver position-dependent and time-dependent values that can be arbitrarily typed. Sensors are bound to a specific sensor node and deliver sensor readings. Readings and sensors can be configured by the user and are referenced inside the simulation using unique names. This decoupling allows changing the underlying reading or sensor implementation without changing or recompiling the simulation code. In its current version, Shawn already provides some simple sensor and reading implementations, which obtain their values from XML files or Tags.
See: Performance