PT-BR: Computação Distribuída
Distributed computing is the field of study that deals with the division of tasks between multiple computers connected in a network.
To ensure effective communication and cooperation between these computers, several standards and concepts are recommended and used.
In the world of distributed systems, where several components work together, some incorrect assumptions can lead to major problems. The eight fallacies of distributed computing, defined by Peter Deutsch and James Gosling, serve as a warning to the dangers of relying on false premises when designing and building these systems.
1. The network is reliable: Believing that the network is always available and free of failures is a myth. In reality, hardware, software, and even internet failures are common. Robust distributed systems need to be designed to handle these failures and ensure the continuity of operations.
2. Latency is zero: Imagine that sending data between computers is instantaneous? This is the idea behind the zero latency fallacy. In practice, latency, the time it takes for data to be transmitted, will always exist. It is crucial to take this into account when designing distributed systems, optimizing communication and minimizing the impacts of latency.
3. Bandwidth is infinite: The amount of data that can be transferred over a network is limited, not infinite. Ignoring this limitation can lead to bottlenecks and slowdowns in the system. It is important to dimension the bandwidth according to the needs of the application and to use data compression techniques when necessary.
4. The network is secure: Believing that the network is a secure environment is a serious mistake. Threats such as hackers, malware, and espionage are always present. Distributed systems need to implement robust security measures to protect data and guarantee the confidentiality of information.
5. Topology does not change: The network structure, such as how computers are connected, can change over time. New machines can be added, old ones can be removed, and even the physical topology of the network can be altered. Flexible distributed systems need to adapt to these changes without compromising their operation.
6. There is only one administrator: In a distributed system, the responsibility for administration can be distributed among several individuals or teams. Believing that there is a single central administrator who controls everything is a misconception. It is necessary to define clear management policies and establish efficient communication and collaboration processes between administrators.
7. Transportation cost is zero: Moving data between computers can have a cost, both in terms of performance and financial resources. Ignoring this cost can lead to inefficient and expensive solutions. It is important to optimize data transfer and consider using techniques such as cache and replication to minimize costs.
8. The network is homogeneous: Distributed systems can be composed of different types of computers, with varying resources and capabilities. Believing that all computers are the same is a mistake. It is essential to consider the heterogeneity of the network when designing the system and distributing tasks efficiently.
By understanding and avoiding these fallacies, you will be on the right track to building robust, scalable, and secure distributed systems, ready for the challenges of the real world.
Remember that the fallacies of distributed computing serve as a guide, not as absolute rules. Each distributed system has its unique characteristics, and it is up to architects and developers to evaluate each case carefully and make the appropriate decisions to ensure the success of the project.
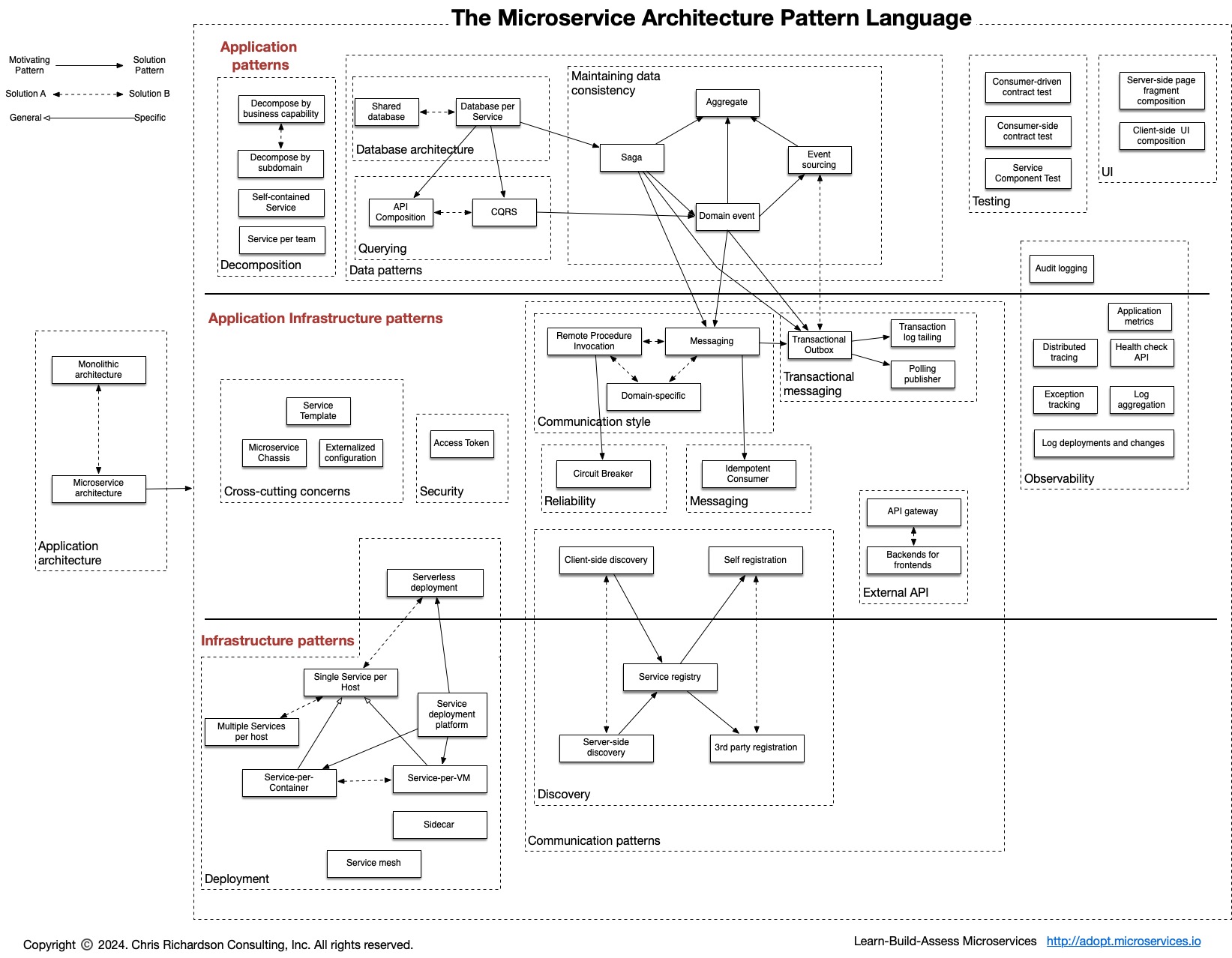
Process of gathering information from different distributed sources. Imagine gathering sales data from multiple stores into a central database.
When an operation fails, this pattern attempts to retry it after a certain time, avoiding temporary errors. Imagine trying to send an email, but the network is congested. The Retry Pattern would try to resend the email later.
If attempts at an operation fail repeatedly, this pattern "breaks the circuit" temporarily, avoiding useless attempts and protecting the system from overload. Returning to the email example, after several failures, the Circuit Breaker would prevent further attempts for a while, avoiding overloading the email server.
Ensures that multiple executions of the same operation have the same effect. It is useful in scenarios where failures can cause resends. Imagine checking out an item from a shopping cart. Even if the checkout is attempted twice, the item will only be checked out once.
Allows a component to send messages to several other interested components, without having to know each one individually. Imagine a news system where an editor publishes a news item, and all users subscribed to that topic receive it.
Coordinates a series of distributed transactions, ensuring the overall consistency of the system. Imagine an online purchase order. The SAGA can ensure that the stock is reserved, the payment is processed, and the shipment is confirmed, reverting everything if any step fails.
Used for messages that need to be sent asynchronously. Imagine an e-commerce that generates a purchase receipt after payment. The Outbox stores the receipt generation message to be sent later, decoupling the order processing from the receipt generation.
Distributed transactions in a system are coordinated to ensure that all parties involved agree to commit or abort the transaction as a whole. This prevents only some parts of the transaction from being updated while others remain in an inconsistent state.
Mechanism by which a component informs other components about the occurrence of an event. Imagine a user registering on a website. The event notification tells other components of the system.
Involves sending all the data necessary to perform an action along with the event notification. Imagine canceling an order. The notification can include all the order details so that the cancellation system can process it directly.
Bases the persistence of the state of a system on a sequence of events that have occurred. Imagine a bank transaction history. Event Sourcing stores each deposit and withdrawal as events, allowing the balance to be reconstructed at any time.
Allows sending a request and receiving a response later, without blocking the requester. Imagine sending an email. The sending can be asynchronous, freeing the system to continue other tasks while the email is sent.
Uses queues to buffer messages and decouple production from consumption. Imagine a print queue. Documents are added to the queue and printed individually, without the program that sent them needing to worry about the printer being busy.
Allows multiple consumers to process messages from a queue concurrently. Imagine a queue of tasks. Several computers can pick up tasks from the queue and process them simultaneously, increasing performance.
Guarantees that data replicated in different locations will eventually become consistent, allowing for availability and scalability. Imagine a sales system with stores spread out. A promotion can lead to temporary price differences until the replication propagates to all stores.
Divides a large database into smaller parts to improve performance and scalability. Imagine a social network with millions of users. The Sharding Pattern can divide user data into smaller shards, facilitating queries and updates.
Separates the components that write data (commands) from those that read data (queries). Imagine an online store. CQRS can separate the product registration system (command) from the product search system (query), optimizing each one for its specific function.
Strategy for gradually migrating a monolithic system to a microservices architecture. Inspired by a plant that grows around a host tree, the pattern involves building new modular services that replace specific functionalities of the monolith while it remains running.
Establishes rules, processes, and controls to manage a distributed system securely and reliably. Imagine the traffic on a highway. Governance defines the traffic rules, enforcement, and maintenance to ensure the smooth functioning of the system.
Stores information about events used in the system, facilitating the discovery and integration of components. Imagine an event dictionary. The event catalog defines the meaning and data associated with each event type, enabling components to understand the notifications received.
Manages the evolution of message schemas used in communication between components. Imagine the grammar of a language. The Schema Registry defines the structure of messages to ensure that components speak the same language and interpret data correctly.
Endpoint that allows checking the health of a service. Imagine checking the engine temperature of a car. The Healthcheck Endpoint provides information about the status of the service, assisting in problem diagnosis.
Allows services to advertise their availability and location, enabling other services to find them. Imagine a phone book for services. The Service Registry & Discovery works like a catalog where services register and can be located by other components that need them.
Helper container that runs alongside the main container. Sidecar provides additional functionality such as monitoring, logging, reverse proxy, security and others.
Collects and analyzes performance and health data from a distributed system. Imagine the dashboards in a car showing speed, RPM, and temperature. Monitoring provides insights into how the system is working, helping to identify and resolve problems.
Understands the internal behavior of a distributed system. Imagine a mechanic examining a car engine. Observability goes beyond monitoring, allowing you to investigate problems and understand the internal workings of the system.
Monitors the flow of requests in a distributed system. Imagine tracking the delivery of a package by different carriers. Distributed tracing identifies bottlenecks and performance problems in the request processing chain.
Centralizes and organizes logs from various components of a distributed system. Imagine centralizing the toll receipts for a trip. Aggregation makes it easier to analyze and correlate events across the entire system.
Automatically adjusts compute resources for a service based on demand. Imagine car headlights that adjust to external light. Auto Scaling scales the system to handle load spikes and optimize resource utilization.
Automatically distributes network traffic among multiple servers to optimize the performance and reliability of a system, preventing a single server from becoming overloaded.
- NGINX
- HAProxy
- Traefik
- Envoy
- Amazon Elastic Load Balancing
- Azure Load Balancer
- Google Cloud Load Balancing
- Docker
- Kubernetes
- Helm
- Rancher
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)