{kind=link}
یکی از ابزارهای مهم جهت استخراج اطلاعات از متن، شناسایی موجودیتهای نامدار (Named Entity Recognition) است. تشخیص موجودیتهای نامدار (نامی) به این معناست که اسامی خاص در یک متن را بتوان تشخیص داد و آنها را به ردههای مشخصی دستهبندی کرد.
این مخزن حاوی پیکرهای از اطلاعات برچسبخورده استاندارد است. اطلاعات از ویکیپدیای فارسی استخراج شدهاند و در حال حاضر شامل حدود بیست و پنج میلیون توکن در قالب حدود یک میلیون جمله است
این پیکره به صورت اپنسورس منتشر شده است. همه پژوهشگران و علاقمندان میتوانند به رایگان از آن استفاده کنند. برای بهبود برچسبهای این پیکره میتوانید به سایت زیر مراجعه کنید: https://app.text-mining.ir
در کمتر از یک ماه از راهاندازی پروژه، تا کنون حدود ۳۰۰ نفر از کاربران در بهبود این پیکره نقش داشتهاند. لیست کامل مشارکتکنندگان (تا زمان انتشار فایل) را از اینجا میتوانید مشاهده کنید
بعد از ثبتنام و ورود، با مراجعه به بخش «برچسبزنی متن NER» . راهنما و مثالهای برچسبزدن متون در این بخش درج شده است و به راحتی میتوانید برچسب کلمات را تغییر دهید.
مراجعه کنید
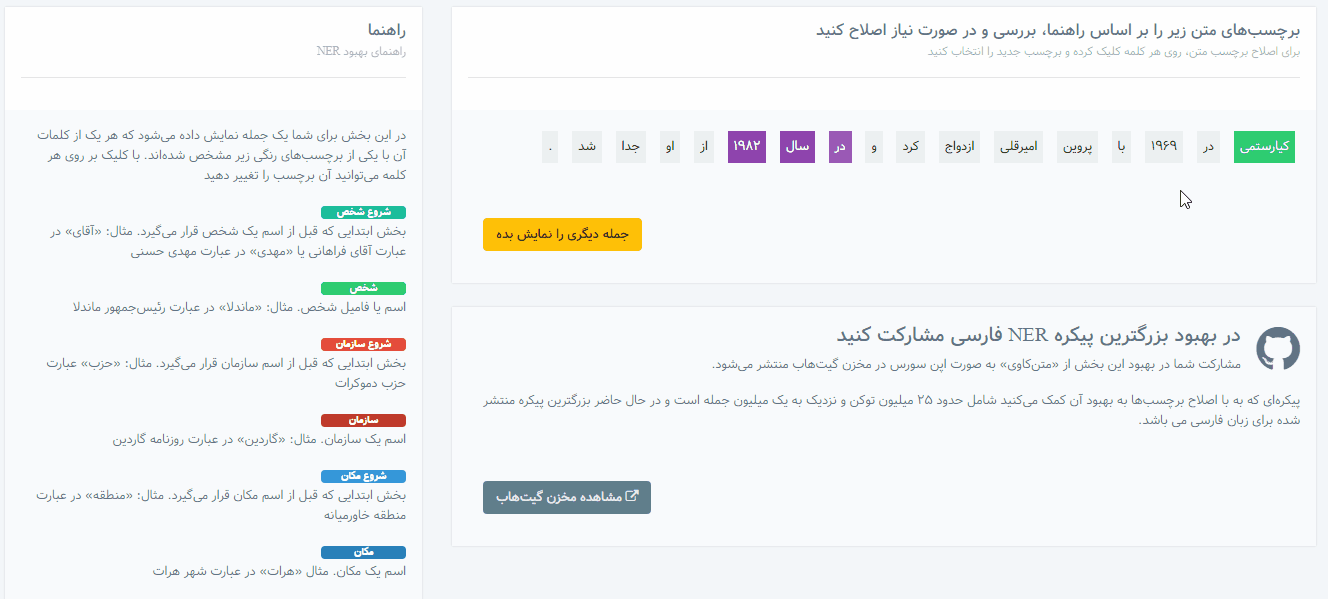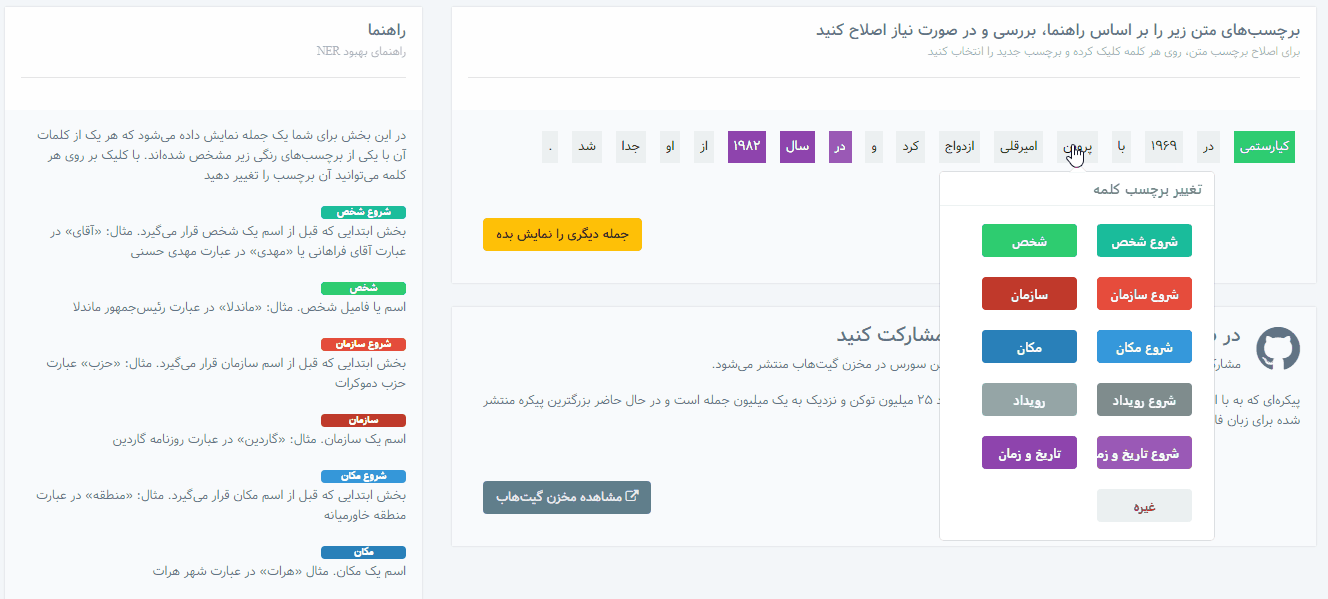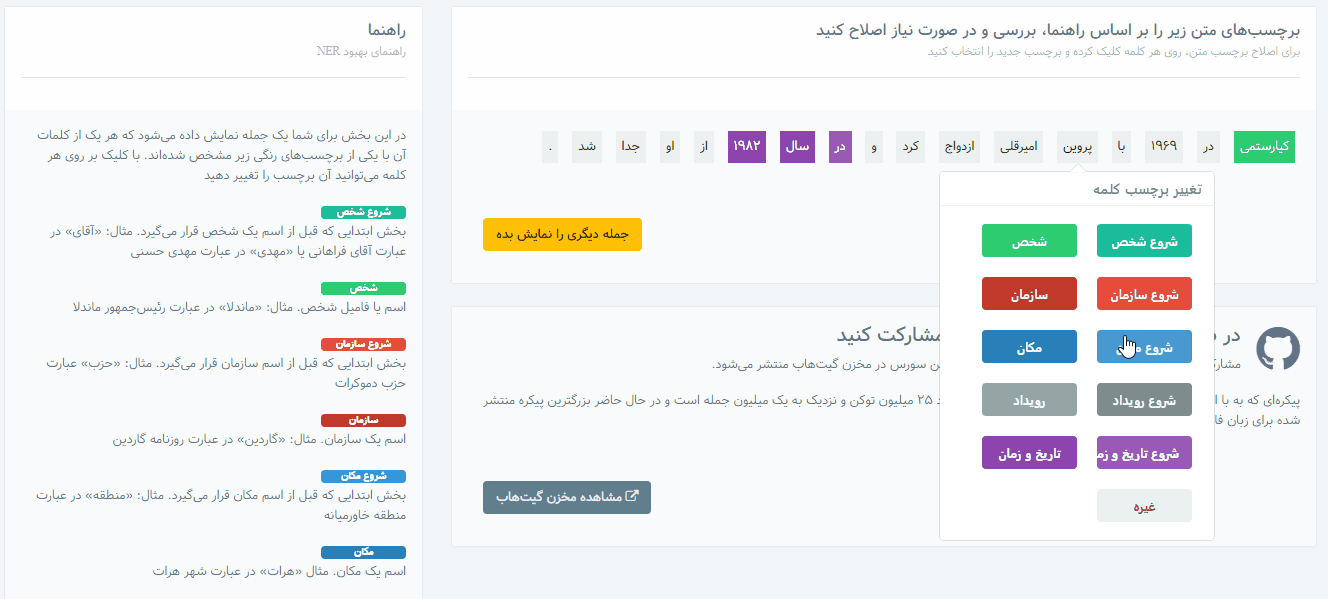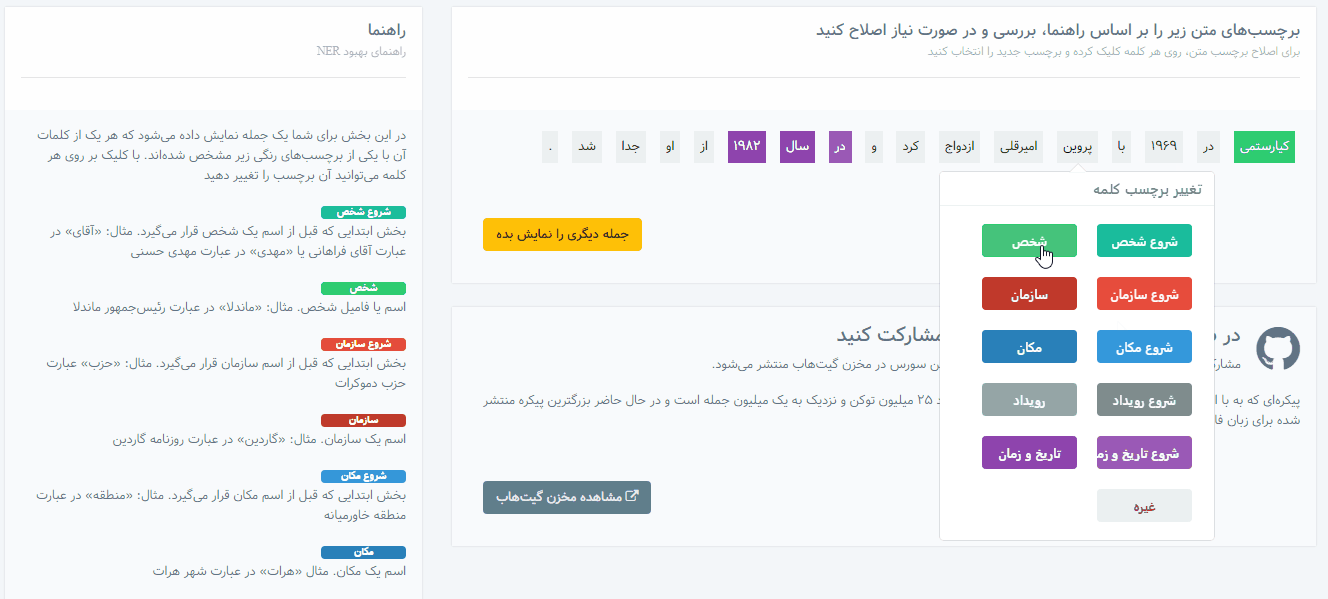
اطلاعات موجود در این مخزن، بر اساس دستهبندیهای زیر برچسبگذاری شدهاند:
- نام شخص (نام کوچک یا فامیل افراد و القاب و عناوین منتسب و یا همراه آنها)
- نام سازمان (شرکت، نهادها، ادارات و تشکلهای خصوصی یا دولتی، نام بخشهای ادارات، گروه، تیم یا باشگاه ورزشی، وزارت، نام کارخانه یا نام فروشگاه معروف یا اصناف، نام نشریات و خبرگزاریها و …)
- نام مکان (کشور، استان، شهر، روستا، کوه، رودخانه، دریا، صحرا، بنای تاریخی، خیابان، مجتمع مسکونی، منطقه یا ناحیه خاص، اشاره به مکان مدرسه یا کارخانه یا مغازه یا ایستگاه مترو یا حرم یا … در متن)
- نام یا عبارت رویداد (حادثه، تصادف، قتل، جنگ، سرقت، آتشسوزی، حادثه تروریستی، برگزاری مسابقات مختلف، انتخابات، مذاکرات یا اجلاس، جشن یا کنگره یا … ، توافقنامه، تظاهرات، مناسبت و …)
- عبارت زمان یا تاریخ (روز هفته، ماه، سال، ساعت، تاریخ، قرن، دوره یا عصر زمانی، اشاره به تاریخ یا زمان خاص یا نسبی مثل “دیروز”، “یک ساعت قبل”، “نیمه شب” و …)
API Build Status
Web Panel Build Status