Scrappy is a utility module that helps you scrap web pages using NodeJS without needing to write any logic code.
Scrappy is using scrappers, which are config objects that tells scrappy what to fetch and how to fetch it. Usually most web page scrapping is based on the same code just setting different configuration.
Scrappy was built with that in mind and allows you just to define scrappers objects and get whatever you want.
All you need to do is understand how to create scrappers and you are ready-to-go!
Since most scrappers are the same, i have also added a scrappers object with some pre-cooked scrappers that you might want to use.
npm install @mrharel/scrappy --save
var scrappy = require('@mrharel/scrappy');
scrappy.get({
url:"http://finance.yahoo.com/news/facebooks-mark-zuckerberg-says-most-130903427.html"
}, (response, error)=>{
if( error ){
console.log("error: ", error);
}
console.log(response);
});
So for this url http://finance.yahoo.com/news/facebooks-mark-zuckerberg-says-most-130903427.html
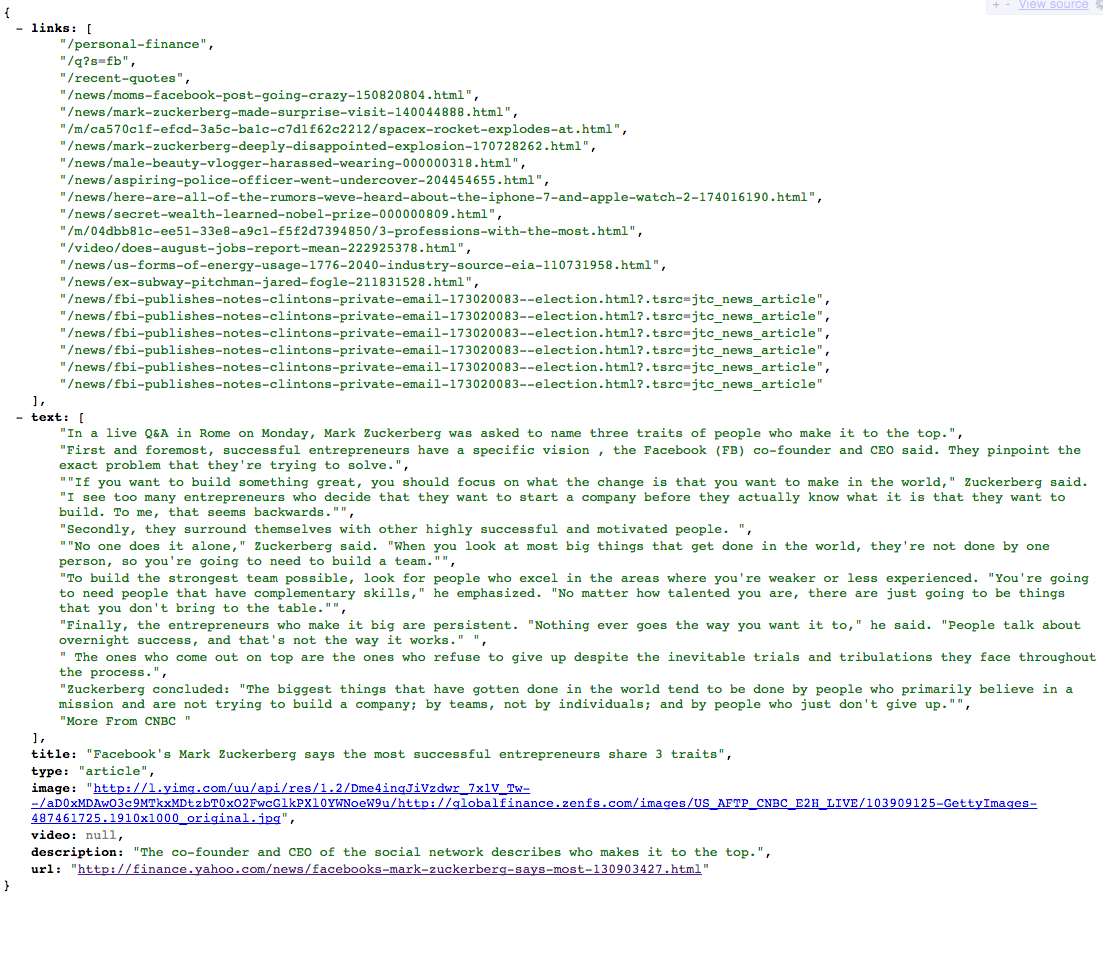
should return something like this:
In this example i am showing how to create a simple api that return the ranking of the players by scrapping the atp website using scrappy.
Click this image to watch the youtube video example.
{kind=link}
{kind=link}
scrappy.get(config,callback)
main function to get scrap parts from a web page.
config either string or an object.
if this is a string it is used as the url to fetch the webpage and scrapp it. In this case only the scrappy.scrappers.openGraph is used by default.
if this is an object here are the options:
- url: the url of the webpage to fetch
- $: cheerio context. provide a loaded cheerio object
cheerio.load(html);so scrappy will use it as the scrapping context. if this is provided scrappy will ignore the url param. You can use this option if you want to load the page yourself. - loader: function which will get the url provided, and a callback method to be invoke when the html was loaded. use this option if you want to load the webpage yourself.
- html: provide an html string. if this is provided the url is ignored.
- scrappers: this is an object where the keys are the name of scrappers and the value is the scrappers object.
callback
funciton(response, error) this function will be called with the final response or error.
scrappy.scrappers
scrappy has a built in scrappers to help you scrap webpages even faster. just mix some of the scrappers according to your needs and you are good to go.
Here is the current scrappers provided by the scrappy moddule:
Open Graph
scrappy.scrappers.openGraph
Use this scrappers to get most of the open graph meta tags.
Images
var relative = scrappy.scrappers.images.relative; //find images which has relative image source
var base64 = scrappy.scrappers.images.base64; //find images which has base64 images
Video
scrappy.scrappers.video.youtube - scrap youtube videos in the page.
scrappy.scrappers.video.vimeo - scrap vimeo videos in the page.
This is where scrappy shines. All you have to understand is how to define scrappers and that is it. If my grandma understand it, so can you.
A scrapper is an object which tell scrappy which elements in the page we want to fine, the value we want to extract from them and what values should we to filter from teh one we found.
You can provide an array of scrappers if you want to crete some fallbacks, or if you just want to have different sscrappers for the same result.
Lets see first all the options a scrapper object can have:
- selector: css selector to find element/s within the webpage. (since we use cheerio, any css selector that it support is accepted here)
- dataType: "html","text","attr"; this control what do you want to take from the element.
- attrName: if dataType is "attr" then this should be the name of the attribute you want.
- valueFn:
function($element, cb)provide a function in case you want to extract the value from the element yourself. the function gets in the first parameter the$elementwhich is the cheerio representation of the element. the second parameter is a callback function which you need to provide the value, or null to ignore this element. - onlyOne: if this is true, only one element will be used for getting it's data value. since the css selector can find more than one element, you can tell scrappy to work only on one element.
- whichOne: "first","last", or any index number. use this to control which element you want in case you specified
onlyOne=true. - next: if this is true and you have an array of scrappers, this will tell scrappy to continue to the next one. if this is not provided or this is false, scrappy will only find the first scrappers which was match and will not continue to the next one.
- filter: this is a way to filter out values from the result.
- regex: provide an array of string regular expressions. the values will be matched to these regular expressions and only the ones which will not pass will be filtered out.
- filterValue:
function(value,cb)provide a function to filter a value. the function gets a value and a callback function. call the callback if true or false to tell scrappy if this value is valid. true=valid. - filterElement:
function($element, cb)this is similar to thefilterValuefunction but you will get the element rather the value.
Lets see some examples:
scrappy.get({
url: "http:.....",
scrappy: {
links: [{
selector: "a",
dataType: "attr",
attrName: "href",
filter:{
regex: ["^\/"]
},
next: true
},
{
selector: "a,
dataType: "attr" ,
attrName: "href",
filter: {
regex: ["^https"]
}
}
}]
}
},function(res,err){};
scrappy.get({
url: "http:.....",
scrappy: {
text: [{
selector: "article p",
dataType: "text"
},
{
selector: "p",
dataType: "text
}]
}
},function(res,err){};
in this example we first try to finr p which are inside of an article tag. if scrappy doesn't have any match for this it ill go to the next option with the simpler selector of just any p in the page.
var scrappy = require('@mrharel/scrappy');
var sizeOf = require('image-size');
var url = require('url');
var http = require('http');
var url = "http://adventure-journal.com/2016/09/2016-wildlife-photos-of-the-year-are-simply-epic/";
let scrappers = {
images: {
selector: "img",
valueFn: function($element, cb){
var imgUrl = $element.attr("src");
if( /^\/[^\/]/.test(imgUrl) ){
cb(null);
return;
}
if( /^\/\//.test(imgUrl) ){
imgUrl = "http:" + imgUrl;
}
var options = url.parse(imgUrl);
http.get(options, function (response) {
var chunks = [];
response.on('data', function (chunk) {
chunks.push(chunk);
}).on('end', function() {
var buffer = Buffer.concat(chunks);
var size = sizeOf(buffer);
if( size.width > 1000 ){
cb({
url: imgUrl,
width: size.width,
height: size.height,
type: size.type
});
}
else{
cb(null);
}
});
});
}
}
};
scrappy.get({
url:req.query.url,
scrappers: scrappers
}, (response, error)=>{
if( error ){
console.log("error: ", error);
}
console.log(response);
});
This is what you should get:
{
images: [
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/5188.jpg",
width: 1100,
height: 764,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/4908.jpg",
width: 1100,
height: 761,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/2600.jpg",
width: 1100,
height: 732,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/6668.jpg",
width: 1100,
height: 619,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/3085.jpg",
width: 1100,
height: 730,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/2600-1.jpg",
width: 1100,
height: 732,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/5270.jpg",
width: 1100,
height: 733,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/4221.jpg",
width: 1100,
height: 742,
type: "jpg"
},
{
url: "http://adventure-journal.com/wp-content/uploads/2016/09/5423.jpg",
width: 1100,
height: 734,
type: "jpg"
}
]
}
var scrappers = {
text: {
selector: "article p",
dataType: "html"
}
};
scrappers = Object.assign(scrappers, scrappy.scrappers.openGraph);
did you wrote a cool scrapper? share it with us so others could use it too. either create a pull request or just open an issue with this suggestion.
web scrapping is on the gray area of the web, and you should make sure you understand all the legal issues before scrapping a web site.
that is it, i told you wht i had to, now you are on your own.
Good luck and happy scrapping.