- Introduction
- C++ Data Types, Operators & User I/O
- C++ Conditional Statements
- C++ Iteration Statements
- C++ Break/Continue
- C++ Arrays
- C++ Pointers
- C++ Strings
- C++ Structures, Unions & Enums
- C++ Functions
- C++ OOPS
- C++ -> 1979 -> Bjarne Stroustrup -> Extension of C
- C++ : fast programs, cross-platform, more control over system resources + memory management
- Used to create high performance applications and software systems.
- Major updates
- 2011 -> C++11
- 2014 -> C++14
- 2017 -> C++17
- C++ is one of the world's most popular programming languages.
- Widely used in - operating systems, GUIs, and embedded systems etc.
- C++ is an object-oriented programming language that gives a clear structure to programs and allows code to be reused, lowering development costs.
- With C++, you can develop applications or heavy games that can run on different platforms.
- It is close to other programming languages - C# , Java , which makes it easy for programmers to switch to C++ or vice versa while it is actually very easy to learn.
- The syntax of C++ is almost identical to that of C, as C++ was developed as an extension of C.
- In contrast to C, C++ supports classes and objects, while C does not.
- To start using C++, you need two things:
- A text editor, like Notepad, or an IDE, like VSCode to act as a platform for you to write C++ code.
- A compiler, like GCC->translate C++-code (high-level-language)->low-level language (machine-language) that the computer will understand.
- IDE stands for Integrated Development Environment.
- It is nothing more than an enhanced version of a text editor that helps you write more efficient and nicer code.
- It helps to differentiate different parts of your codes with different colors and notifies you if you are missing some semicolon or bracket at some place by highlighting that area.
- A lot of IDEs are available, such as DEVC++ or Code Blocks, but I will prefer using VS Code.
- Visit https://code.visualstudio.com/download
- Click on the download option as per your operating system.
- After the download is completed, open the setup and run it by saving VS Code in the default location.
- You will need to click the next button again and again until the installation process begins.
- Check all the boxes to open VS code in any directory.

- Used to run the program of a certain language which is generally high-level by converting the code into a language that is low-level that our computer could understand.
- There are a lot of compilers available, but we will proceed with MinGW because it will fulfill all of our requirements, and also it is recommended by Microsoft itself.
- Visit https://code.visualstudio.com/docs/languages/cpp
- Select C++ from the sidebar.
- Choose “GCC via Mingw-w64 on Windows” from the options shown there.
- Select the install sourceforge option.
- After the downloading gets completed, run the setup and choose all the default options.
- Go to the C directory. Navigate into the Program Files. Then, open MinGW-64. Open MinGW-32. And then the bin folder. After reaching the bin, save the path or URL to the bin.
- Then go to the properties of ‘This PC’.
- Select ‘Advanced System Settings’.
- Select the ‘Environment Variable’ option.
- Then select System-variables->Path->Edit->New-> then paste the copied path.
- And now, you can visit your IDE and run your C++ programs on it. The configuration part is done.
- Open VSCode. Here’s the simplest print statement we can start with.
#include <iostream>
int main()
{
std::cout << "Hello World";
return 0;
}Output:
Hello World
Programming in C++ involves following a basic structure throughout. To understand that basic structure, the first program we learned writing in C++ will be referred to.
#include <iostream>
int main()
{
std::cout << "Hello World";
return 0;
}Here’s what it can be broken down to.
It is common for C++ programs to include many built-in elements from the standard C++ library, including classes, keywords, constants, operators, etc. It is necessary to include an appropriate header file in a program in order to use such pre-defined elements.
In the above program, #include <iostream> was the line put to include the header file iostream. The iostream library helps us to get input data and show output data. The iostream library also has many more uses and error facilities; it is not only limited to input and output.
Header file are both system defined and user defined. To know more about header files, go to the documentary here, https://en.cppreference.com/w/cpp/header.
Here, all the variables, or other user-defined data types are declared. These variables are used throughout the program and all the functions.
- After the definition of all the other entities, here we declare all the functions a program needs. These are generally user-defined.
- Every program contains one main parent function which tells the compiler where to start the execution of the program.
- All the statements that are to be executed are written in the main function.
- Only the instructions enclosed in curly braces {} are considered for execution by the compiler.
- After all instructions in the main function have been executed, control leaves the main function and the program ends.
- A C++ program is made up of different tokens combined. These tokens include:
- Keywords
- Identifiers
- Constants
- String Literal
- Symbols & Operators
-> reserved words -> can not be used elsewhere in the program for naming a variable or a function.
-> Have a specific function or task -> Their functionalities are pre-defined.
One such example of a keyword could be return which is used to build return statements for functions. Other examples are auto, if, default, etc.
There is a list of reserved keywords which cannot be reused by the programmer or overloaded. One can find the list here, https://en.cppreference.com/w/cpp/keyword.
-
Identifiers are names given to variables or functions to differentiate them from one another. Their definitions are solely based on our choice but there are a few rules that we have to follow while naming identifiers. One such rule says that the name can not contain special symbols such as @, -, *, <, etc.
-
C++ is a case-sensitive language so an identifier containing a capital letter and another one containing a small letter in the same place will be different. For example, the three words: Code, code, and cOde can be used as three different identifiers.
Constants are very similar to a variable and they can also be of any data type. The only difference between a constant and a variable is that a constant’s value never changes.
String literals or string constants are a sequence of characters enclosed in double quotation("") marks. Escape sequences are also string literals.
Symbols are special characters reserved to perform certain actions. Using them lets the compiler know what specific tasks should be performed on the given data. Several examples of symbols are arithmetical operators such as +, *, or bitwise operators such as ^, &.
A comment is a human-readable text in the source code, which is ignored by the compiler. Comments can be used to insert any informative piece which a programmer does not wish to be executed. It could be either to explain a piece of code or to make it more readable. In addition, it can be used to prevent the execution of alternative code when the process of debugging is done.
Comments can be singled-lined or multi-lined.
- Single-line comments start with two forward slashes (//).
- Any information after the slashes // lying on the same line would be ignored (will not be executed) since they become unparsable.
An example of how we use a single-line comment
#include <iostream>
int main()
{
// This is a single line comment
std::cout << "Hello World";
return 0;
}- A multi-line comment starts with /* and ends with */.
- Any information between /* and */ will be ignored by the compiler.
An example of how we use a multi-line comment
#include <iostream>
int main()
{
/* This is a
multi-line
comment */
std::cout << "Hello World";
return 0;
}- A variable is a container to hold data.
Like for storing something we need containers . Now for different types of things we need different container likewise in C++ to store different types of data we have different datatypes in C++.
C++ provides a layer of abstraction (from low level to high level) where you can represent your data as int, float, double etc.
- Variable can be of various types. Primarily we have these variable types in C++ :
- int - eg. 1,3,2,56,0,...etc.
- float - eg. 1.34, 3.54,...etc.
- char - eg. 'c', 'd', 'a', 'B' ... etc.
- double - it is same as float with more precision. eg. 1.2435 , ... etc.
- boolean - True or False.
- int sum = 36; means sum is an integer variable which holds value 36 in memory.
We cannot declare a variable without specifying its data type. The data type of a variable depends on what we want to store in the variable and how much space we want it to hold. The syntax for declaring a variable is simple:
data_type variable_name;OR
data_type variable_name = value;There is no limit to what we can call a variable. Yet there are specific rules we must follow while naming a variable:
- A variable name in C++ can have a length of range 1 to 255 characters
- A variable name can only contain alphabets, digits, and underscores(_).
- A variable cannot start with a digit.
- A variable cannot include any white space in its name.
- Variable names are case sensitive
- The name should not be a reserved keyword or any special character.
The scope of a variable is the region in a program where the existence of that variable is valid. Based on its scope, variables can be classified into two types:
Local variables:
Local variables are declared inside the braces of any function and can be assessed only from that particular function.
Global variables:
Global variables are declared outside of any function and can be accessed from anywhere.
An example that demonstrates the difference in applications of a local and a global variable is given below.
#include <iostream>
using namespace std;
int a = 5; //global variable
void func()
{
cout << a << endl;
}
int main()
{
int a = 10; //local variable
cout << a << endl;
func();
return 0;
}Output:
10
5
Explanation: A local variable a was declared in the main function, and when printed, gave 10. This is because, within the body of a function, a local variable takes precedence over a global variable with the same name. But since there was no variable declared in the func function, it considered the global variable a for printing, and hence the value 5.
A variable, as its name is defined, can be altered, or its value can be changed, but the same is not true for its type. If a variable is of integer type, it will only store an integer value through a program. We cannot assign a character type value to an integer variable. We can not even store a decimal value into an integer variable.
Data types define the type of data a variable can hold; for example, an integer variable can hold integer data, a character can hold character data, etc.
Data types in C++ are categorized into three groups:
Built-in data types
These data types are pre-defined for a language and could be used directly by the programmer.
Examples are: Int, Float, Char, Double, Boolean
User-defined data types
These data types are defined by the user itself.
Examples are: Class, Struct, Union, Enum
Derived data types
These data types are derived from the primitive built-in data types.
Examples are: Array, Pointer, Function
Some of the popular built-in data types and their applications are:
| Data Type | Size | Description |
|---|---|---|
| int | 2 or 4 bytes | Stores whole numbers, without decimals |
| float | 4 bytes | Stores fractional numbers, containing one or more decimals. They require 4 bytes of memory space. |
| double | 8 bytes | Stores fractional numbers, with more precision. They require 8 bytes of memory space. |
| char | 1 byte | Stores a single character/letter/number, or ASCII values |
| boolean | 1 byte | Stores true or false values |
- For n = size in bits (1 byte = 8 bits)
- Range = -2^(n-1) to 2^(n-1)-1 (for signed)
- Range = 0 to 2*(2^(n-1)-1) (for unsigned)
| Data Type | Size (in Bytes) | Range |
|---|---|---|
| short int | 2 | -32,768 to 32,767 |
| unsigned short int | 2 | 0 to 65,535 |
| unsigned int | 2 | 0 to 4,294,967,295 |
| int | 4 | -2,147,483,648 to 2,147,483,647 |
| long int | 4 | -2,147,483,648 to 2,147,483,647 |
| unsigned long int | 4 | 0 to 4,294,967,295 |
| long long int | 8 | -2^(63) to 2^(63)-1 |
| unsigned long long int | 8 | 0 to 2*(2^(63)-1) |
| signed char | 1 | -128 to 127 |
| unsigned char | 1 | 0 to 255 |
| unsigned char | 1 | 0 to 255 |
| float | 4 | -2^31 to (2^31)-1 |
| double | 8 | -2^63 to (2^63)-1 |
| long double | 12 | -2^95 to (2^95)-1 |
| wchar_t | 2 or 4 | 1 wide character |
Constants are unchangeable; when a constant variable is initialized in a program, its value cannot be changed afterwards.
#include <iostream>
using namespace std;
int main()
{
const float PI = 3.14;
cout << "The value of PI is " << PI << endl;
PI = 3.00; //error, since changing a const variable is not allowed.
}Output:
error: assignment of read-only variable 'PI'
- Arithmetic operators ( +, -, *, /, % )
- Assignment operator (=)
- Compound assignment (+=, -=, *=, /=, %=, >>=, <<=, &=, ^=, |=)
- Increment and decrement (++, --)
- Relational and comparison operators ( ==, !=, >, <, >=, <= )
- Logical operators ( !, &&, || )
- Conditional ternary operator ( ? )
- Comma operator ( , )
- Bitwise operators ( &, |, ^, ~, <<, >> )
To get a list of operator precedence , go to - https://en.cppreference.com/w/cpp/language/operator_precedence
In C++ programming language, manipulators are used in the formatting of output. These are helpful in modifying the input and the output stream. They make use of the insertion and extraction operators to modify the output.
Here’s a list of a few manipulators:
| Manipulators | Description |
|---|---|
| endl | It is used to enter a new line with a flush. |
| setw(a) | It is used to specify the width of the output. |
| setprecision(a) | It is used to set the precision of floating-point values. |
| setbase(a) | It is used to set the base value of a numerical number. |
Let’s see their implementation in C++. Note that we use the header file iomanip for some of the manipulators.
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
int main()
{
float PI = 3.14;
int num = 100;
cout << "Entering a new line." << endl;
cout << setw(10) << "Output" << endl;
cout << setprecision(5) << M_PI << endl;
cout << setbase(16) << num << endl; // sets base to 16
}OUTPUT
Entering a new line.
Output
3.1416
64
C++ language comes with different libraries which helps us in performing input/output. In C++ sequence of bytes corresponding to input and output are commonly known as streams.There are two types of streams. They are,
- Input Stream: Direction of flow of bytes takes place from input device (eg.- Keyboard) to the main memory.
- Output Stream: Direction of flow of bytes takes place from main memory to the output device (eg.- Display).
An example that demonstrates how input and output are popularly done in C++.
#include <iostream>
using namespace std;
int main()
{
int num;
cout << "Enter a number: ";
cin >> num; // Getting input from the user
cout << "Your number is: " << num; // Displaying the input value
return 0;
}Input:
Enter a number: 10
Output:
Your number is: 10
Important Points
- The sign << is called the insertion operator (inserting on the display).
- The sign >> is called the extraction operator (extracting user input).
- cout keyword is used to print.
- cin keyword is used to take input at run time.
The work of control structures is to give flow and logic to a program. There are three types of basic control structures in C++
- Sequence Structure - refers to the sequence in which program execute instructions one after another.
- Selection Structure (if..else , if..else if..else , switch..case) - refers to the execution of instruction according to the selected condition, which can be either true or false.
- Loop Structure (for , while , do...while) - refers to the execution of an instruction in a loop until the condition gets false.
1. Sequence Structure ---> Entry ---> Action1 ---> Action2 ---> Exit
2. Selection Structure ---> Entry ---> Condition --> if true --> Action1 ---> if false --> Action2 ---> Exit
3. Loop Structure ---> Entry ---> Condition --> if true --> Action1 in loop until termination ---> if false --> Action2 ---> Exit
Syntax :
if ( condition ) {
//statements;
}
else if ( condition ) {
//statements;
}
else {
//statements;
}Note: The else if statement checks for a different condition if the conditions checked above it evaluate to false.
The control statement that allows us to make a decision effectively from the number of choices is called a switch, or a switch case-default since these three keywords go together to make up the control statement.
Switch executes that block of code, which matches the case value. If the value does not match with any of the cases, then the default block is executed.
Syntax :
switch (integer / character expression)
{
case {value 1}:
//do this;
break;
case {value 2}:
//do this;
break;
default:
//do this;
}The break keyword in a case block indicates the end of a particular case. If we do not put the break in each case, then even though the specific case is executed, the switch will continue to execute all the cases until the end is reached.
- The need to perform an action, again and again, with little or no variations in the details each time they are executed is met by a mechanism known as a loop.
- This involves repeating some code in the program, either a specified number of times or until a particular condition is satisfied.
- Loop-controlled instructions are used to perform this repetitive operation efficiently ensuring the program doesn’t look redundant at the same time due to the repetitions.
Following are the three types of loops in C++ programming.
- For Loop
- While Loop
- Do While Loop
A for loop is a repetition control structure that allows us to efficiently write a loop that will execute a specific number of times. The for-loop statement is very specialized. We use a for loop when we already know the number of iterations of that particular piece of code we wish to execute. Although, when we do not know about the number of iterations, we use a while loop which is discussed next.
Here is the syntax of a for loop in C++ programming.
for (initialise counter; test counter; increment / decrement counter)
{
//set of statements
}Here,
- initialize counter: It will initialize the loop counter value. It is usually i=0.
- test counter: This is the test condition, which if found true, the loop continues, otherwise terminates.
- Increment/decrement counter: Incrementing or decrementing the counter.
- Set of statements: This is the body or the executable part of the for loop or the set of statements that has to repeat itself.
A While loop is also called a pre-tested loop. A while loop allows a piece of code in a program to be executed multiple times, depending upon a given test condition which evaluates to either true or false. The while loop is mostly used in cases where the number of iterations is not known. If the number of iterations is known, then we could also use a for loop as mentioned previously.
Following is the syntax for using a while loop.
while (condition test)
{
// Set of statements
}The body of a while loop can contain a single statement or a block of statements. The test condition may be any expression that should evaluate as either true or false. The loop iterates while the test condition evaluates to true. When the condition becomes false, it terminates.
A do-while loop is a little different from a normal while loop. A do-while loop, unlike what happens in a while loop, executes the statements inside the body of the loop before checking the test condition.
So even if a condition is false in the first place, the do-while loop would have already run once. A do-while loop is very much similar to a while loop, except for the fact that it is guaranteed to execute the body at least once.
Unlike for and while loops, which test the loop condition first, then execute the code written inside the body of the loop, the do-while loop checks its condition at the end of the loop.
Following is the syntax for using a do-while loop.
do
{
//statements;
} while (test condition);First, the body of the do-while loop is executed once. Only then, the test condition is evaluated. If the test condition returns true, the set of instructions inside the body of the loop is executed again, and the test condition is evaluated. The same process goes on until the test condition becomes false. If the test condition returns false, then the loop terminates.
One such example to demonstrate how a do-while loop works is
#include <iostream>
using namespace std;
int main()
{
int i = 5;
do
{
cout << i << " ";
i++;
} while (i < 5);
return 0;
}Output
5
Here, even if i was less than 5 from the very beginning, the do-while let the print statement execute once, and then terminated.
Break statement is used to break the loop or switch case statements execution and brings the control to the next block of code after that particular loop or switch case it was used in.
Break statements are used to bring the program control out of the loop it was encountered in. The break statement is used inside loops or switch statements in C++ language.
One such example to demonstrate how a break statement works is
#include <iostream>
using namespace std;
int main()
{
int num = 10;
int i;
for (i = 0; i < num; i++)
{
if (i == 6)
{
break;
}
cout << i << " ";
}
return 0;
}Output
0 1 2 3 4 5
Here, when i became 6, the break statement got executed and the program came out of the for loop.
The continue statement is used inside loops in C++ language. When a continue statement is encountered inside the loop, the control jumps to the beginning of the loop for the next iteration, skipping the execution of statements inside the body of the loop after the continue statement.
It is used to bring the control to the next iteration of the loop. Typically, the continue statement skips some code inside the loop and lets the program move on with the next iteration. It is mainly used for a condition so that we can skip some lines of code for a particular condition.
It forces the next iteration to follow in the loop unlike a break statement, which terminates the loop itself the moment it is encountered.
One such example to demonstrate how a continue statement works is
#include <iostream>
using namespace std;
int main()
{
for (int i = 0; i <= 10; i++)
{
if (i < 6)
{
continue;
}
cout << i << " ";
}
return 0;
}Output
6 7 8 9 10
Here, the continue statement was continuously executing while i remained less than 5. For all the other values of i, we got the print statement working.
An array is a collection of items that are of the same data type stored in contiguous memory locations. And it is also known as a subscript variable. It can even store the collection of derived data types such as pointers, structures, etc.
An array can be of any dimension. The C++ Language places no limits on the number of dimensions in an array. This means we can create arrays of any number of dimensions. It could be a 2D array or a 3D array or more.
- It is used to represent multiple data items of the same type by using only a single name.
- Accessing any random item at any random position in a given array is very fast in an array.
- There is no case of memory shortage or overflow in the case of arrays since the size is fixed and elements are stored in contiguous memory locations.
- Without specifying the size of the array:
int arr[] = {1, 2, 3};Here, we can leave the square brackets empty, although the array cannot be left empty in this case. It must have elements in it.
- With specifying the size of the array:
int arr[3];
arr[0] = 1, arr[1] = 2, arr[2] = 3;An element in an array can easily be accessed through its index number.
An index number is a special type of number which allows us to access variables of arrays. Index number provides a method to access each element of an array in a program. This must be remembered that the index number starts from 0 and not one.
Example:
#include <iostream>
using namespace std;
int main()
{
int arr[] = {1, 2, 3};
cout << arr[1] << endl;
}Output:
2
An element in an array can be overwritten using its index number.
Example:
#include <iostream>
using namespace std;
int main()
{
int arr[] = {1, 2, 3};
arr[2] = 8; //changing the element on index 2
cout << arr[2] << endl;
}Output:
8
& is also known as the Referencing Operator. It is a unary operator. The variable name used along with the Address of operator must be the name of an already defined variable.
Using & operator along with a variable gives the address number of the variable.
Here’s one example to demonstrate the use of the address of the operator.
#include <iostream>
using namespace std;
int main()
{
int a = 10;
cout << "Address of variable a is " << &a << endl;
return 0;
}Output:
Address of variable a is 0x61ff0c
* is also known as the Dereferencing Operator. It is a unary operator. It takes an address as its argument and returns the content/container whose address is its argument.
Here’s one example to demonstrate the use of the indirection operator.
#include <iostream>
using namespace std;
int main()
{
int a = 100;
cout << "Value of variable a stored at address " << &a << " is " << (*(&a)) << endl;
return 0;
}Output:
Value of variable a stored at address 0x61ff0c is 100
Pointer to Pointer is a simple concept, in which we store the address of one pointer to another pointer. This is also known as multiple indirections owing to the operator’s name. Here, the first pointer contains the address of the second pointer, which points to the address where the actual variable has its value stored.
An example to demonstrate how we define a pointer to a pointer.
#include <iostream>
using namespace std;
int main()
{
int a = 100;
int *b = &a;
int **c = &b;
cout << "Value of variable a is " << a << endl;
cout << "Address of variable a is " << b << endl;
cout << "Address of pointer b is " << c << endl;
return 0;
}Output:
Value of variable a is 100
Address of variable a is 0x61ff08
Address of pointer b is 0x61ff04
Storing the address of an array into pointer is different from storing the address of a variable into the pointer. The name of an array itself is the address of the first index of an array. So, to use the (ampersand)& operator with the array name for assigning the address to a pointer is wrong. Instead, we used the array name itself.
An example program for storing the starting address of an array in the pointer,
int marks[] = {99, 100, 38};
int *p = marks;
cout << "The value of marks[0] is " << *p << endl;Output:
The value of marks[0] is 99
In order to access other elements of the same array that pointer p points to, we can use pointer arithmetic, such as addition and subtraction of pointers.
*(p+1) returns the value at the second position in the array marks. Here’s how it works.
int marks[] = {99, 100, 38};
int *p = marks;
cout << "The value of marks[0] is " << *p << endl;
cout << "The value of marks[1] is " << *(p + 1) << endl;
cout << "The value of marks[2] is " << *(p + 2) << endl;Output:
The value of marks[0] is 99
The value of marks[1] is 100
The value of marks[2] is 38
A string is an array of characters. Unlike in C, we can define a string variable and not necessarily a character array to store a sequence of characters. Data of the same type are stored in an array, for example, integers can be stored in an integer array, similarly, a group of characters can be stored in a character array or a string variable. A string is a one-dimensional array of characters.
Declaring a string is very simple, the same as declaring a one-dimensional array. It’s just that we are considering it as an array of characters.
Below is the syntax for declaring a string.
string string_name ;In the above syntax, string_name is any name given to the string variable and it can be given a string input later or it can even be initialised at the time of definition.
string string_name = "Aman Kumar Gupta";Example of a string:
#include <iostream>
#include <string>
using namespace std;
int main()
{
// declare and initialise string
string str = "Aman Kumar Gupta";
// user input string
string str1;
cout << "Enter string : ";
getline(cin, str1);
cout << str << endl
<< str1;
return 0;
}Output:
Enter string : Welcome IIIT Sophomore!!
Aman Kumar Gupta
Welcome IIIT Sophomore!!
Note: To be able to use these strings, you must declare another header file named string. It contains a lot of useful string functions and libraries as well.
Variables store only one piece of information and arrays of certain data types store the information of the same data type. Variables and arrays can handle a great variety of situations. But quite often, we have to deal with the collection of dissimilar data types. For dealing with cases where there is a requirement to store dissimilar data types, C++ provides a data type called ‘structure’. The structure is a user-defined data type that is available in C++. Structures are used to combine different types of data types, just like an array is used to combine the same type of data types.
Another way to store data of dissimilar data types would have been constructing individual arrays, but that must be unorganized. It is to keep in mind that structure elements too are always stored in contiguous memory locations.
- We can assign the values of a structure variable to another structure variable of the same type using the assignment operator.
- Structure can be nested within another structure which means structures can have their members as structures themselves.
- We can pass the structure variable to a function. We can pass the individual structure elements or the entire structure variable into the function as an argument. And functions can also return a structure variable.
- We can have a pointer pointing to a struct just like the way we can have a pointer pointing to an int, or a pointer pointing to a char variable.
We use the struct keyword to define the struct.
The basic syntax for declaring a struct is,
struct structure_name
{
//structure_elements
} structure_variable;Here’s one example of how a struct is defined and used in main as a user-defined data type.
#include <iostream>
using namespace std;
struct employee
{
/* data */
int eId;
char favChar;
int salary;
};
int main()
{
struct employee Aman;
return 0;
}To access any of the values of a structure's members, we use the dot operator (.). This dot operator is coded between the structure variable name and the structure member that we wish to access.
Before the dot operator, there must always be an already defined structure variable and after the dot operator, there must always be a valid structure element.
Here’s one example demonstrating how we access struct elements.
#include <iostream>
using namespace std;
struct employee
{
/* data */
int eId;
char favChar;
int salary;
};
struct employee e1;
int main()
{
struct employee Aman;
Aman.eId = 1;
Aman.favChar = 'c';
Aman.salary = 120000000;
cout << "eID of Aman is " << Aman.eId << endl;
cout << "favChar of Aman is " << Aman.favChar << endl;
cout << "salary of Aman is " << Aman.salary << endl;
e1 = Aman; // assigning value of Aman to e1
cout << e1.eId << endl;
return 0;
}Output:
eID of Aman is 1
favChar of Aman is c
salary of Aman is 120000000
1
Just like Structures, the union is a user-defined data type. They provide better memory management than structures. All the members in the unions share the same memory location.
The union is a data type that allows different data belonging to different data types to be stored in the same memory locations. One of the advantages of using a union over structures is that it provides an efficient way of reusing the memory location, as only one of its members can be accessed at a time. A union is used in the same way we declare and use a structure. The difference lies just in the way memory is allocated to their members.
We use the union keyword to define the union.
The syntax for defining a union is,
union union_name
{
//union_elements
} union_variable;Here’s one example of how a union is defined and used in main as a user-defined data type.
#include <iostream>
using namespace std;
union money
{
/* data */
int rice;
char car;
float pounds;
};
int main()
{
union money m1;
}Different from how we used to initialise a struct in one single statement, union elements are initialised one at a time.
And also, one can access only one union element at a time. Altering one union element disturbs the value stored in other union elements.
#include <iostream>
using namespace std;
union money
{
/* data */
int rice;
char car;
float pounds;
};
int main()
{
union money m1;
m1.rice = 34;
cout << m1.rice;
return 0;
}Output:
34
Note: We can only use 1 variable at a time otherwise the compiler will give us a garbage value and the compiler chooses the data type which has maximum memory for the allocation.
Enum or enumeration is a user-defined data type. Enums have named constants that represent integral values. Enums are used to make the program more readable and less complex. It lets us define a fixed set of possible values and later define variables having one of those values.
We use the enum keyword to define the enum.
The syntax for defining a union is,
enum enum_name
{
element1,
element2,
element3
};Here’s one example of how a union is defined and used in main as a user-defined data type.
enum Meal
{
breakfast,
lunch,
dinner
};Since every enum element gets assigned a value to it, they could be used to compare if a particular variable store the same value.
#include <iostream>
using namespace std;
enum Meal
{
breakfast,
lunch,
dinner
};
int main()
{
Meal m1 = dinner;
Meal m2 = lunch;
if (m1 == 2)
{
cout << "The value of dinner is " << dinner << endl;
}
if (m2 == 0)
{
cout << "The value of breakfast is " << breakfast << endl;
}
else
cout << "The value of breakfast is not equal to " << m2 << endl;
}Output:
The value of dinner is 2
The value of breakfast is not equal to 1
Functions are the main part of top-down structured programming. We break the code into small pieces and make functions of that code. Functions could be called multiple or several times to provide reusability and modularity to the C++ program.
Functions are also called procedures or subroutines or methods and they are often defined to perform a specific task. And that makes functions a group of code put together and given a name that can be called anytime without writing the whole code again and again in a program.
- The use of functions allows us to avoid re-writing the same logic or code over and over again.
- With the help of functions, we can divide the work among the programmers.
- We can easily debug or can find bugs in any program using functions.
- They make code readable and less complex.
- Declaration: This is where a function is declared to tell the compiler about its existence.
- Definition: A function is defined to get some task executed. (It means when we define a function, we write the whole code of that function and this is where the actual implementation of the function is done).
- Call: This is where a function is called in order to be used.
The function prototype is the template of the function which tells the details of the function which include its name and parameters to the compiler. Function prototypes help us to define a function after the function call.
// Function prototype
return_datatype function_name(datatype_1 a, datatype_2 b);
// writing a and b is optional in function prototypeLibrary functions are pre-defined functions in C++ Language. These are the functions that are included in C++ header files prior to any other part of the code in order to be used.
E.g. sqrt(), abs(), etc.
User-defined functions are functions created by the programmer for the reduction of the complexity of a program. Rather, these are functions that the user creates as per the requirements of a program.
E.g. Any function created by the programmer (displayArray(), .... etc).
A function receives information that is passed to them as a parameter. Parameters act as variables inside the function.
Parameters are specified collectively inside the parenthesis after the function name. Parameters inside the parenthesis are comma separated.
We have different names for different parameters.
So, the variable which is declared in the function is called a formal parameter or simply, a parameter. For example, variables a and b are formal parameters.
int sum(int a, int b){ // formal parameters
//function body
}The values which are passed to the function are called actual parameters or simply, arguments. For example, the values num1 and num2 are arguments.
int sum(int a, int b);
int main()
{
int num1 = 5;
int num2 = 6;
sum(num1, num2); // actual parameters
}A function doesn't need to have parameters or it should necessarily return some value.
eg-
#include <iostream>
using namespace std;
void greet() { cout << "Hello World!!"; }
int main()
{
greet();
}OUTPUT
Hello World!!
Now, there are methods using which arguments are sent to the function. They are,
In the case of call by value the copies of actual parameters are sent to the formal parameter, which means that if we change the values inside the function that will not affect the actual values.
An example that demonstrates the call by value method is,
#include <iostream>
using namespace std;
void swap(int a, int b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int x = 5, y = 6;
cout << "The value of x is " << x << " and the value of y is " << y << endl;
swap(x, y);
cout << "The value of x is " << x << " and the value of y is " << y << endl;
}Output:
The value of x is 5 and the value of y is 6
The value of x is 5 and the value of y is 6
In the case of call by pointer, the address of actual parameters is sent to the formal parameter, which means that if we change the values inside the function that will affect the actual values.
An example that demonstrates the call by pointer method is,
#include <iostream>
using namespace std;
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
int main()
{
int x = 5, y = 6;
cout << "The value of x is " << x << " and the value of y is " << y << endl;
swap(&x, &y);
cout << "The value of x is " << x << " and the value of y is " << y << endl;
}Output:
The value of x is 5 and the value of y is 6
The value of x is 6 and the value of y is 5
In the case of call by reference, the reference of actual parameters is sent to the formal parameter, which means that if we change the values inside the function that will affect the actual values.
An example that demonstrates the call by reference method is,
#include <iostream>
using namespace std;
void swap(int &a, int &b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int x = 5, y = 6;
cout << "The value of x is " << x << " and the value of y is " << y << endl;
swap(x, y);
cout << "The value of x is " << x << " and the value of y is " << y << endl;
}Output
The value of x is 5 and the value of y is 6
The value of x is 6 and the value of y is 5
Two special methods that are often used by programmers to have their program work efficiently are,
Default arguments are those values which are used by the function if we don’t input our value as parameter. It is recommended to write default arguments after the other arguments.
An example using default argument,
int sum(int a, int b = 5);
// always write default arguments from rightmost sideConstant arguments are used when you don’t want your values to be changed or modified by the function. The const keyword is used to make the parameters non-modifiable.
An example using constant argument,
int sum(const int a, int b);When a function calls itself, it is called recursion and the function which is calling itself is called a recursive function. The recursive function consists of a base condition and a recursive condition.
Recursive functions must be designed with a base case to make sure the recursion stops, otherwise, they are bound to execute forever and that's not what you want. The case in which the function doesn’t recur is called the base case. For example, when we try to find the factorial of a number using recursion, the case when our number becomes smaller than 1 is the base case.
An example of a recursive function is the function for calculating the factorial of a number.
int factorial(int n){
if (n == 0 || n == 1){
return 1;
}
return n * factorial(n - 1);
}Function overloading is a process to make more than one function with the same name but different parameters, numbers, or sequences. Now, there are a few conditions and any number of functions with the same name following any of these are called overloaded.
Example
float sum(int a, int b);
float sum(float a, float b);Example
float sum(int a, int b);
float sum(int a, int b, int c);Example
float sum(int a, float b);
float sum(float a, int b);Exact matches are always preferred while looking for a function that has the same set of parameters.
- OOP stands for Object-Oriented Programming. An object-oriented programming language uses objects in its programming. Programming with object-oriented concepts aims to emulate real-world concepts such as inheritance, polymorphism, abstraction, etc, in a program.
- C++ language was designed with the main intention of adding object-oriented programming to C language. As the size of the program increases, the readability, maintainability, and bug-free nature of the program decrease. The main aim of OOP is to bind together the data and the functions that operate on them so that no other part of the code can access this data except that function.
- This was the major problem with languages like C which relied upon functions or procedures (hence the name procedural programming language). As a result, the possibility of not addressing the problem adequately was high. Also, data was almost neglected, and data security was easily compromised. Using classes solves this problem by modeling the program as a real-world scenario.
Procedure Oriented Programming
- Consists of writing a set of instructions for the computer to follow.
- The main focus is on functions and not on the flow of data.
- Functions can either use local or global data.
- Data moves openly from function to function.
Object - Oriented Programming
- Works on the concept of classes and object.
- A class is a template to create objects.
- Treats data as a critical element.
- Decomposes the problem in objects and builds data and functions around the objects.
Basically, procedural programming involves writing procedures or functions that manipulate data, while object-oriented programming involves creating objects that contain both data and functions.
- Classes - Basic template for creating objects. This is the building block of object-oriented programming.
- Objects – Basic run-time entities and instances of a class.
- Data Abstraction & Encapsulation – Wrapping data and functions into a single unit.
- Inheritance – Properties of one class can be inherited into others.
- Polymorphism – Ability to take more than one form.
- Dynamic Binding – Code which will execute is not known until the program runs.
- Message Passing – message (Information) call format.
Object-oriented programming has many advantages. Listed below are a few.
- Programs involving OOP is faster and easier to execute.
- By using objects and inheritance, it provides a clear structure for programs and improves code reusability.
- It makes the code easier to maintain, modify and debug.
- Principle of data hiding helps build secure systems
- Multiple Objects can co-exist without any interference
- Software complexity can be easily managed so that even the creation of fully reusable software with less code and shorter development time is possible.
Classes and structures are somewhat the same but still, they have some differences. For example, we cannot hide data in structures which means that everything is public and can be accessed easily which is a major drawback of the structure because structures cannot be used where data security is a major concern. Another drawback of structures is that we cannot add functions to them.
Classes are user-defined data types and are a template or blueprint for creating objects. Classes consist of variables and functions which are also called class members.
We use the class keyword to define a class in C++.
The syntax of a class in C++ is
class class_name
{
//body of the class
};Objects are instances of a class. To create an object, we just have to specify the class name and then the object’s name. Objects can access class attributes and methods which are bound to the class definition. It is recommended to put these attributes and methods in access modifiers so that their permissions can be better specified to allow them to be used by objects.
The syntax for defining an object in C++ is
class class_name
{
//body of the class
};
int main()
{
class_name object_name; //object
}Class attributes and methods are variables and functions that are defined inside the class. They are also known as class members altogether.
Consider an example below to understand what class attributes are
#include <iostream>
using namespace std;
class Employee
{
string eID;
string eName;
int ePhone;
public:
};
int main()
{
Employee Aman;
}A class named Employee is built and three members, eId, eName and ePhone are defined inside the class. These three members are variables and are known as class attributes. Now, an object named Aman is defined in the main. Aman can access these attributes using the dot operator. But they are not accessible to Aman unless they are made public.
#include <iostream>
using namespace std;
class Employee
{
public:
string eID;
string eName;
long long int ePhone;
};
int main()
{
Employee Aman;
Aman.eID = "B121006";
Aman.eName = "Aman Kumar Gupta";
Aman.ePhone = 9983229291;
cout << "Employee having ID " << Aman.eID << " is " << Aman.eName << endl;
cout << "Employee contact number : " << Aman.ePhone;
}Output
Employee having ID B121006 is Aman Kumar Gupta
Employee contact number : 9983229291
Class methods are nothing but functions that are defined in a class or belong to a class. Methods belonging to a class are accessed by their objects in the same way that they access attributes. Functions can be defined in two ways so that they belong to a class.
An example that demonstrates defining functions inside classes is
class Employee
{
public:
int eID;
string eName;
void printName()
{
cout << eName << endl;
}
};Although, a function can be defined outside the class, it needs to be declared inside. Later, we can use the scope resolution operator (::) to define the function outside.
An example that demonstrates defining functions outside classes is
class Employee
{
public:
int eID;
string eName;
void printName();
};
void Employee::printName()
{
cout << eName << endl;
}The way memory is allocated to variables and functions of the class is different even though they both are from the same class. The memory is only allocated to the variables of the class when the object is created.
The memory is not allocated to the variables when the class is declared. At the same time, single variables can have different values for different objects, so every object has an individual copy of all the variables of the class. But the memory is allocated to the function only once when the class is declared. So the objects don’t have individual copies of functions only one copy is shared among each object.
When a static data member is created, there is only a single copy of the data member which is shared between all the objects of the class. Usually, every object has an individual copy of the attributes unless specified statically.
Static members are not defined by any object of the class. They are exclusively defined outside any function using the scope resolution operator.
An example of how static variables are defined is
class Employee
{
public:
static int count; //returns number of employees
string eName;
void setName(string name)
{
eName = name;
count++;
}
};
int Employee::count = 0; //defining the value of countWhen a static method is created, they become independent of any object and class. Static methods can only access static data members and static methods. Static methods can only be accessed using the scope resolution operator. An example of how static methods are used in a program is shown.
#include <iostream>
using namespace std;
class Employee
{
public:
static int count; //static variable
string eName;
void setName(string name)
{
eName = name;
count++;
}
static int getCount()//static method
{
return count;
}
};
int Employee::count = 0; //defining the value of count
int main()
{
Employee Aman;
Aman.setName("Aman");
cout << Employee::getCount() << endl;
}Output:
1
Friend functions are those functions that have the right to access the private data of members of the class even though they are not defined inside the class. It is necessary to write the prototype of the friend function.
Declaring a friend function inside a class does not make that function a member of the class.
- Not in the scope of the class, means it is not a member of the class.
- Since it is not in the scope of the class, it cannot be called from the object of that class.
- Can be declared anywhere inside the class, be it under the public or private access modifier, it will not make any difference.
- It cannot access the members directly by their names, it needs (object_name.member_name) to access any member.
The syntax for declaring a friend function inside a class is
class class_name
{
friend return_type function_name(arguments);
};
return_type class_name::function_name(arguments)
{
//body of the function
}Friend classes are those classes that have permission to access private members of the class in which they are declared. The main thing to note here is that if the class is made friends of another class then it can access all the private members of that class.
The syntax for declaring a friend class inside a class is
class class_name
{
friend class friend_class_name;
};A constructor is a special member function with the same name as the class. The constructor doesn’t have a return type. Constructors are used to initialize the objects of their class. Constructors are automatically invoked whenever an object is created.
- A constructor should be declared in the public section of the class.
- They are automatically invoked whenever the object is created.
- They cannot return values and do not have return types.
- It can have default arguments.
An example of how a constructor is used is,
#include <iostream>
using namespace std;
class Employee
{
public:
static int count; //returns number of employees
string eName;
//Constructor
Employee()
{
count++; //increases employee count every time an object is defined
}
void setName(string name)
{
eName = name;
}
static int getCount()
{
return count;
}
};
int Employee::count = 0; //defining the value of count
int main()
{
Employee Aman1;
Employee Aman2;
Employee Aman3;
cout << Employee::getCount() << endl;
}Output:
3
Parameterized constructors are those constructors that take one or more parameters. Default constructors are those constructors that take no parameters. This could have helped in the above example by passing the employee name at the time of definition only. That should have removed the setName function.
Constructor overloading is a concept similar to function overloading. Here, one class can have multiple constructors with different parameters. At the time of definition of an instance, the constructor, which will match the number and type of arguments, will get executed.
For example, if a program consists of 3 constructors with 0, 1, and 2 arguments and we pass just one argument to the constructor, the constructor which is taking one argument will automatically get executed.
Default arguments of the constructor are those which are provided in the constructor declaration. If the values are not provided when calling the constructor the constructor uses the default arguments automatically.
An example that shows declaring default arguments is
class Employee
{
public:
Employee(int a, int b = 9);
};A copy constructor is a type of constructor that creates a copy of another object. If we want one object to resemble another object we can use a copy constructor. If no copy constructor is written in the program compiler will supply its own copy constructor.
The syntax for declaring a copy constructor is
class class_name
{
int a;
public:
//copy constructor
class_name(class_name &obj)
{
a = obj.a;
}
};The act of hiding information.
Encapsulation is the first pillar of Object Oriented Programming. It means wrapping up data attributes and methods together. The goal is to keep sensitive data hidden from users.
Encapsulation is considered a good practice where one should always make attributes private for them to become non-modifiable until needed. The data is ultimately more secure as a result of this. Once members are made private, methods to access them or change them should be declared.
An example of how encapsulation is achieved is
#include <iostream>
using namespace std;
class class_name
{
private:
int a;
public:
void setA(int num)
{
a = num;
}
int getA()
{
return a;
}
};
int main()
{
class_name obj;
obj.setA(5);
cout << obj.getA() << endl;
}Output:
5
A process thorough which a derived class acquires the properties of a base class.
The concept of reusability in C++ is supported using inheritance. We can reuse the properties of an existing class by inheriting it and deriving its properties. The existing class is called the base class and the new class which is inherited from the base class is called the derived class.
The syntax for inheriting a class is
// Derived Class syntax
class derived_class_name : access_modifier base_class_name
{
// body of the derived class
}- Single Inheritance
Single inheritance is a type of inheritance in which a derived class is inherited with only one base class.
For example, we have two classes ClassA and ClassB. If ClassB is inherited from ClassA, it means that ClassB can now implement the functionalities of ClassA. This is single inheritance.
class ClassA
{
//body of ClassA
};
//derived from ClassA
class ClassB : public ClassA
{
//body of ClassB
};- Multiple Inheritance
Multiple inheritances is a type of inheritance in which one derived class is inherited from more than one base class.
For example, we have three classes ClassA, ClassB, and ClassC. If ClassC is inherited from both ClassA & ClassB, it means that ClassC can now implement the functionalities of both ClassA & ClassB. This is multiple inheritances.
class ClassA
{
//body of ClassA
};
class ClassB
{
//body of ClassB
};
//derived from ClassB and Class C
class ClassC : public ClassA, public ClassB
{
//body of ClassC
};- Hierarchical Inheritance
A hierarchical inheritance is a type of inheritance in which several derived classes are inherited from a single base class.
For example, we have three classes ClassA, ClassB, and ClassC. If ClassB and Class C are inherited from ClassA, it means that ClassB and ClassC can now implement the functionalities of ClassA. This is hierarchical inheritance.
class ClassA
{
//body of ClassA
};
//derived from ClassA
class ClassB : public ClassA
{
//body of ClassB
};
//derived from ClassA
class ClassC : public ClassA
{
//body of ClassC
};- Multilevel Inheritance
Multilevel inheritance is a type of inheritance in which one derived class is inherited from another derived class.
For example, we have three classes ClassA, ClassB, and ClassC. If ClassB is inherited from ClassA and ClassC is inherited from ClassB, it means that ClassB can now implement the functionalities of ClassA and ClassC can now implement the functionalities of ClassB. This is multilevel inheritance.
class ClassA
{
//body of ClassA
};
//derived from ClassA
class ClassB : public ClassA
{
//body of ClassB
};
//derived from ClassB
class ClassC : public ClassB
{
//body of ClassC
};- Hybrid Inheritance
Hybrid inheritance is a combination of different types of inheritances.
For example, we have four classes ClassA, ClassB, ClassC, and ClassD. If ClassC is inherited from both ClassA and ClassB and ClassD is inherited from ClassC, it means that ClassC can now implement the functionalities of both ClassA and ClassB and ClassD can now implement the functionalities of ClassC. This is multilevel inheritance where both multilevel and multiple inheritances are present.
class ClassA
{
//body of ClassA
};
class ClassB
{
//body of ClassB
};
//derived from ClassA and ClassA
class ClassC : public ClassA, public ClassB
{
//body of ClassC
};
//derived from ClassC
class ClassD : public ClassC
{
//body of ClassD
};All the variables and functions declared under the public access modifier will be available for everyone. They can be accessed both inside and outside the class. Dot (.) operator is used in the program to access public data members directly.
All the variables and functions declared under a private access modifier can only be used inside the class. They are not permissible to be used by any object or function outside the class.
Protected access modifiers are similar to the private access modifiers but protected access modifiers can be accessed in the derived class whereas private access modifiers cannot be accessed in the derived class.
A table is shown below which shows the behavior of access modifiers when they are derived from public, private, and protected.
| Public derivation | Private Derivation | Protected Derivation | |
|---|---|---|---|
| Private members | Not inherited | Not inherited | Not inherited |
| Protected Members | Protected | Private | Protected |
| Public Members | Public | Private | Protected |
- If the class is inherited in public mode then its private members cannot be inherited in child class.
- If the class is inherited in public mode then its protected members are protected and can be accessed in child class.
- If the class is inherited in public mode then its public members are public and can be accessed inside the child class and outside the class.
- If the class is inherited in private mode then its private members cannot be inherited in child class.
- If the class is inherited in private mode then its protected members are private and cannot be accessed in child class.
- If the class is inherited in private mode then its public members are private and cannot be accessed in child class.
- If the class is inherited in protected mode then its private members cannot be inherited in child class.
- If the class is inherited in protected mode then its protected members are protected and can be accessed in the child class.
- If the class is inherited in protected mode then its public members are protected and can be accessed in the child class.
Poly means several and morphism means form. Polymorphism is something that has several forms or we can say it as one name and multiple forms.
There are two types of polymorphism:
- Compile-time polymorphism
- Run time polymorphism
In compile-time polymorphism, it is already known which function will run. Compile-time polymorphism is also called early binding, which means that you are already bound to the function call and you know that this function is going to run.
There are two types of compile-time polymorphism:
-
Function Overloading
This is a feature that lets us create more than one function and the functions have the same names but their parameters need to be different. When function overloading is implemented in a program and function calls are made, the compiler knows which functions to execute. -
Operator Overloading
This is a feature that lets us define operators working for some specific tasks. Using the operator +, we can add two strings by concatenating and add two numerical values arithmetically at the same time. This is operator overloading.
With run-time polymorphism, the compiler has no idea what will happen when the code is executed. Run time polymorphism is also called late binding. The run-time polymorphism is considered slow because function calls are decided at run time. Run time polymorphism can be achieved from virtual functions.
A member function in the base class that is declared using a virtual keyword is called a virtual function. They can be redefined in the derived class. A function that is in the parent class but redefined in the child class is called a virtual function.
For a function to become virtual, it should not be static.
Overview
- Abstraction
- Encapsulation
- Inheritance
- Polymorphism
Abstraction
Providing essential features, but hiding the bacground details.
A user is aware of the fact that what a user defined type is capable of doing. Or what are the functionalities attached to that UDT. But not aware of the fact that how these are implemented.
For example, stack as a UDT. We can push an element to the stack and pop an element from the stack. But the user cannot know how the stack is implemented. A stack may either be implemented with the help of a linked list or with an array.
Polymorphism
It is a combination of two words namely poly means many and morphs means forms.
In OOPs, a function can take many forms according to different circumstances. Same function can behave differently with different signature. This polymorphic behavior can be static or dynamic.
-
The way memory is allocated to variables and functions of the class is different even though they both are from the same class.
-
The memory is only allocated to the variables of the class when the object is created.
-
The memory is not allocated to the variables when the class is declared.
-
At the same time, single variables can have different values for different objects, so every object has an individual copy of all the variables of the class.
-
Memory is allocated to the function only once when the class is declared. So the objects don’t have individual copies of functions only one copy is shared among each object.
- We can use contructors in derived classes in C++.
- If base class constructor does not have any arguments, there is no need of any constructor in derived class.
- But if there are one or more arguments in the base class constructor, derived class need to pass arguments to the base class constructor.
- If both base and derived classes have constructors, base class constructor is executed first.
- In multiple inheritance, base classes are constructed in the order in which they appear in the class declaration.
- In multilevel inheritance, the constructors are executed in the order of inheritance.
- C++ supports an special syntax for passing arguments to multiple base classes.
- The constructor of the derived class receives all the arguments at once and then will pass the calls to the respective base classes.
- The body is called after all the construcotrs are finished executing.
Derived-Constructor(arg1, arg2, arg3,...) : Base1-Constructor(arg1, arg2), Base2-Constructor(arg3, arg4) {
// Statements
} Base1-Constructor(arg1, arg2)- The constructors for virtual base classes are invoked before an non-virtual base class.
- If there are multiple virutal base classes, they are invoked in the order declared.
- Any non-virtual base class are then constructed before the derived class constructor is executed.
Polymorphism in C++
“Poly” means several and “morphism” means form. So we can say that polymorphism is something that has several forms or we can say it as one name and multiple forms. There are two types of polymorphism:
- Compile-time polymorphism
- Run time polymorphism
Compile Time Polymorphism
In compile-time polymorphism, it is already known which function will run. Compile-time polymorphism is also called early binding, which means that you are already bound to the function call and you know that this function is going to run. There are two types of compile-time polymorphism:
-
Function Overloading This is a feature that lets us create more than one function and the functions have the same names but their parameters need to be different. If function overloading is done in the program and function calls are made the compiler already knows that which functions to execute.
-
Operator Overloading This is a feature that lets us define operators working for some specific tasks. For example, we can overload the operator “+” and define its functionality to add two strings. Operator loading is also an example of compile-time polymorphism because the compiler already knows at the compile time which operator has to perform the task.
Run Time Polymorphism
In the run-time polymorphism, the compiler doesn’t know already what will happen at run time. Run time polymorphism is also called late binding. The run time polymorphism is considered slow because function calls are decided at run time. Run time polymorphism can be achieved from the virtual function.
- Virtual Function A function that is in the parent class but redefined in the child class is called a virtual function. “virtual” keyword is used to declare a virtual function.
Pure Virtual Functions in C++
Pure virtual function is a function that doesn’t perform any operation and the function is declared by assigning the value 0 to it. Pure virtual functions are declared in abstract classes.
Abstract Base Class in C++
Abstract base class is a class that has at least one pure virtual function in its body. The classes which are inheriting the base class must need to override the virtual function of the abstract class otherwise compiler will throw an error.
Roadmap:
- What is a template in C++ programming?
- Why templates?
- Syntax
What is a template in C++ programming?
A template is believed to escalate the potential of C++ several fold by giving it the ability to define data types as parameters making it useful to reduce repetitions of the same declaration of classes for different data types. Declaring classes for every other data type(which if counted is way too much) in the very first place violates the DRY( Don’t Repeat Yourself) rule of programming and on the other doesn't completely utilise the potential of C++.
It is very analogous to when we say classes are the templates for objects, here templates itself are the templates of the classes. That is, what classes are for objects, templates are for classes.
Why templates?
- DRY Rule:
To understand the reason behind using templates, we will have to understand the effort behind declaring classes for different data types. Suppose we want to have a vector for each of the three(can be more) data types, int, float and char. Then we’ll obviously write the whole thing again and again making it awfully difficult. This is where the saviour comes, the templates. It helps parametrizing the data type and declaring it once in the source code suffice. Very similar to what we do in functions. It is because of this, also called, ‘parameterized classes’.
- Generic Programming:
It is called generic, because it is sufficient to declare a template once, it becomes general and it works all along for all the data types.
Refer to the schematic below:
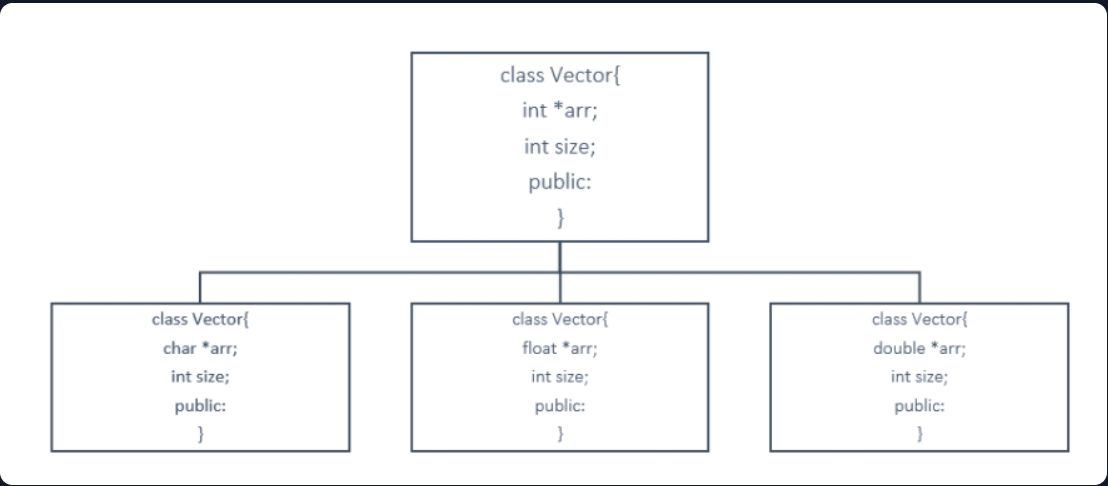
We had to copy the same thing again and again for different data types, but a template solves it all. Refer to the syntax section for how.
Below is the template for a vector of int data type, and it goes similarly for float char double, etc.
class vector {
int *arr;
int size;
public:
};Syntax:
Understanding the syntax below:
-
First, we declare a template of class and pass a variable T as its parameter.
-
Define the class of vector and keep the data type of *arr as T only. Now, the array becomes of the type we supply in the template.
Now we can easily use this template to declare umpteen number of classes in our main scope. Be it int, float, or arr vector.
#include <iostream>
using namespace std;
template <class T>
class vector {
T *arr;
int size;
public:
vector(T* arr)[
//code
]
//and many other methods
};
int main() {
vector<int> myVec1();
vector<float> myVec2();
return 0;
}Templates are believed to be very useful for people who pursue competitive programming. It makes their work several folds easier. It gives them an edge over others. It is a must because it saves you a lot of time while programming.
Why is this important for competitive programmers?
-
Competitive programming is a part of various environments, be it job interviews, coding contests and all, and if you’re in one of those environments, you’ll be given limited time to code your program.
-
So, suppose you want in your program, a resizable array, or sort an array or any other data structure. or search for some element in your container.
-
You will always try to code a function which will execute the above mentioned things, and end up losing a great amount of time. But here is when you will use STL.
An STL is a library of generic functions and classes which saves you time and energy which you would have spent constructing for your use. This helps you reuse these well tested classes and functions umpteenth number of times according to your own convenience.
To put this simply, STL is used because it is not a good idea to reinvent something which is already built and can be used to innovate things further. Suppose you go to a company who builds cars, they will not ask you to start from scratch, but to start from where it is left. This is the basic idea behind using STL.
COMPONENTS OF STL:
We have three components in STL:
- Containers
- Algorithm
- Iterators
Let’s deal with them individually;
Containers:
Container is an object which stores data. We have different containers having their own benefits. These are the implemented template classes for our use, which can be used just by including this library. You can even customise these template classes.
Algorithms:
Algorithms are a set of instructions which manipulates the input data to arrive at some desired result. In STL, we have already written algorithms, for example, to sort some data structure, or search some element in an array. These algorithms use template functions.
Iterators:
Iterators are objects which refer to an element in a container. And we handle them very much similarly to a pointer. Their basic job is to connect algorithms to the container and play a vital role in manipulation of the data.
I’ll give you a quick illustration of how they work combinedly.
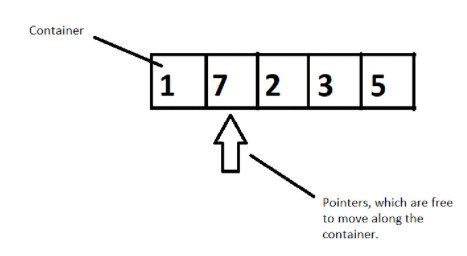
Figure 1: Illustration of how these three components work together
Suppose we have a container of integers, and we want to sort them in ascending order. We will have pointers which will help moving elements to places by pointing to it, following a well-constructed algorithm. So, here a container gets sorted by following an algorithm by the use of pointers. This is how they work in accordance with each other.
So, this was the basics of STL and the motivation behind using it in your programs.
In the last topic, we had briefed about the three components of STL, namely,
Containers, objects which store data, Algorithms, set of procedures to process data, and Iterators, objects which point to some element in a container. Now, we will be interested in discussing more about containers.
Containers are themselves of three types:
- Sequence Containers
- Associative Containers
- Derived Containers
When we talked about containers, we said containers are objects which store data, but what are its three types all about? We’ll discuss that too.
- Sequence Containers
A sequence container stores that data in a linear fashion. Refer to the illustration below to understand what storing something in a linear fashion means.
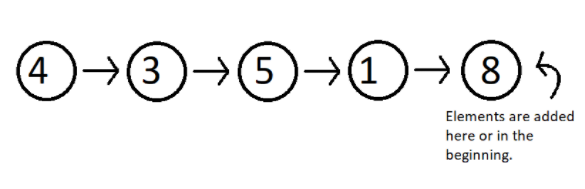
Figure 1: Elements stored in a linear fashion
Sequence containers include Vector, List, Dequeue etc. These are some of the most used sequence containers.
- Associative Containers
An associative container is designed in such a way that enhances the accessing of some element in that container. It is very much used when the user wants to fastly reach some element. Some of these containers are, Set, Multiset, Map, Multimap etc. They store their data in a tree-like structure.
- Derived Containers
As the name suggests, these containers are derived from either the sequence or the associative containers. They often provide you with some better methods to deal with your data. They deal with real life modelling. Some examples of derived containers are Stack, Queue, Priority Queue, etc. The following illustration give you the idea of how a stack works.
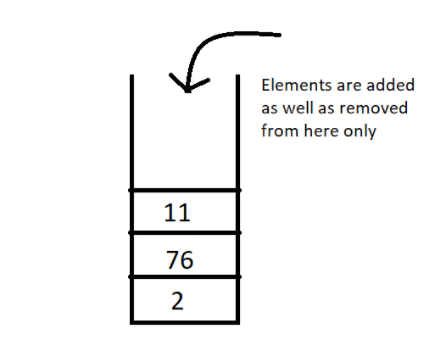
Figure 3: A stack, works on the first in first out [FIFO] method
Now since we have got the basic idea of all the three types of containers, a question which might arise is when to use which. So, let’s deal with that,
In sequence containers, we have Vectors, which has following properties:
- Faster random access to elements in comparison to array
- Slower insertion and deletion at some random position, except at the end.
- Faster insertion at the end.
In Lists, we have,
- Random accessing elements is too slow, because every element is traversed using pointers.
- Insertion and deletion at any position is relatively faster, because they only use pointers, which can easily be manipulated.
- In associative containers, every operation except random access is faster in comparison to any other containers, be it inserting or deleting any element.
In associative containers, we cannot specifically tell which operation is faster or slower, we’ll have to inspect every data structure separately.
- Header file - Contain a set of predefined standard library functions.It enhances code functionality and readability.
- You request to use a header file in your program by including it with the C preprocessing directive "#include".
- All the header file have a '.h' extension.
- In C++, all the header files may or may not end with the '.h' extension but in C, all the header files must necessarily end with the '.h' extension.
- A header file contains:
- Function definitions
- Data type definitions
- Macros
- '#include' is preprocessor directive used for instructing compiler that header files need to be processed before compilation.
- There are of 2 types of header file:
- Pre-existing header files: Files which are already available in C/C++ compiler we just need to import them.
- User-defined header files: These files are defined by the user and can be imported using "#include".
Syntax
#include <filename.h>
// or
#include "filename.h"Note: We can’t include the same header file twice in any program.
You can use various header files in a program. When a header file is included twice within a program, the compiler processes the contents of that header file twice. This leads to an error in the program. To eliminate this error, conditional preprocessor directives are used.
Syntax:
#ifndef HEADER_FILE_NAME
#define HEADER_FILE_NAME
the entire header file
#endifThis construct is called wrapper "#ifndef". When the header is included again, the conditional will become false, because HEADER_FILE_NAME is defined. The preprocessor will skip over the entire contents of the file and the compiler will not see it twice.
Sometimes it’s essential to include several diverse header files based on the requirements of the program. For this, multiple conditionals are used.
Syntax:
#if SYSTEM_ONE
#include "system1.h"
#elif SYSTEM_TWO
#include "system2.h"
#elif SYSTEM_THREE
....
#endifStandard Header Files And Their Uses:
#include<stdio.h>: It is used to perform input and output operations using functions scanf() and printf().#include<iostream>: It is used as a stream of Input and Output using cin and cout.#include<string.h>: It is used to perform various functionalities related to string manipulation like strlen(), strcmp(), strcpy(), size(), etc.#include<math.h>: It is used to perform mathematical operations like sqrt(), log2(), pow(), etc.#include<iomanip.h>: It is used to access set() and setprecision() function to limit the decimal places in variables.#include<signal.h>: It is used to perform signal handling functions like signal() and raise().#include<stdarg.h>:It is used to perform standard argument functions like va_start() and va_arg(). It is also used to indicate start of the variable-length argument list and to fetch the arguments from the variable-length argument list in the program respectively.#include<errno.h>: It is used to perform error handling operations like errno(), strerror(), perror(), etc.#include<fstream.h>: It is used to control the data to read from a file as an input and data to write into the file as an output.#include<time.h>: It is used to perform functions related to date() and time() like setdate() and getdate(). It is also used to modify the system date and get the CPU time respectively.#include<float.h>: It contains a set of various platform-dependent constants related to floating point values. These constants are proposed by ANSI C. They allow making programs more portable. Some examples of constants included in this header file are- e(exponent), b(base/radix), etc.#include<limits.h>: It determines various properties of the various variable types. The macros defined in this header, limits the values of various variable types like char, int, and long. These limits specify that a variable cannot store any value beyond these limits, for example an unsigned character can store up to a maximum value of 255.#include<assert.h>: It contains information for adding diagnostics that aid program debugging.#include<ctype.h>: It contains function prototypes for functions that test characters for certain properties , and also function prototypes for functions that can be used to convert uppercase letters to lowercase letters and vice versa.#include<locale.h>: It contains function prototypes and other information that enables a program to be modified for the current locale on which it’s running. It enables the computer system to handle different conventions for expressing data such as times, dates or large numbers throughout the world.#include<setjmp.h>: It contains function prototypes for functions that allow bypassing of the usual function call and return sequence.#include<stddef.h>: It contains common type definitions used by C for performing calculations.
Non-Standard Header File And its Uses:
#include<bits/stdc++.h>: It contains all standard library of the header files mentioned above. So if you include it in your code, then you need not have to include any other standard header files. But as it is a non-standard header file of GNU C++ library, so, if you try to compile your code with some compiler other than GCC it might fail; e.g. MSVC do not have this header. (See this article for more reference)