find the previous version of this document at crankshaft/compiler.md
Fully activated with V8 version 5.9. Earliest LTS Node.js release with a TurboFan activated pipleline is Node.js V8.
Table of Contents generated with DocToc
- Goals
- Simplified Pipeline
- Advantages Over Old Pipeline
- Ignition Interpreter
- Collecting Feedback via ICs
- TurboFan
- Speculative Optimization
- Deoptimization
- Background Compilation
- Sea Of Nodes
- CodeStubAssembler
- Recommendations
- Resources
Speed up real world performance for modern JavaScript, and enable developers to build a faster future web.
- fast startup vs. peak performance
- low memory vs. max optimization
- Ignition Interpreter allows to run code with some amount of optimization very quickly and has very low memory footprint
- TurboFan makes functions that run a lot fast, sacrificing some memory in the process
- designed to support entire JavaScript language and make it possible to quickly add new features and to optimize them fast and incrementally
slide: pipeline 2010 | slide: pipeline 2014 | slide: pipeline 2016 | slide: pipeline 2017
Once crankshaft was taken out of the mix the below pipeline was possible
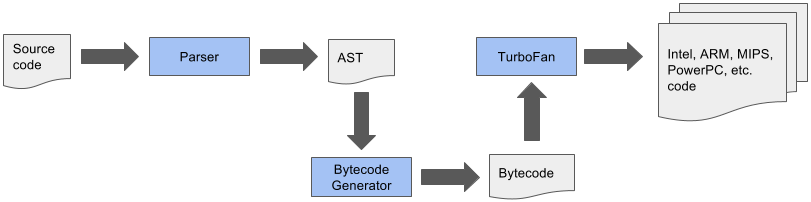
- Parse JavaScript into an AST (abstract syntax tree)
- Generate bytecode from that AST
- Turn bytecode into sequence of bytecodes by the BytecodeGenerator, which is part of the Ignition Interpreter
- sequences are divided on a per function basis
- Execute bytecode sequences via Ignition and collect feedback via inline caches
- feedback used by Ignition itself to speed up subsequent interpretation of the bytecode
- feedback used for speculative optimization by TurboFan when code is optimized
- Speculatively optimize and compile bytecode using collected feedback to generate optimized machine code for the current architecture


watch old architecture | watch new architecture
- reduces memory and startup overhead significantly
- AST no longer source of truth that compilers need to agree on
- AST much simpler and smaller in size
- TurboFan uses Ignition bytecode directly to optimize (no re-parse needed)
- bytecode is 25-50% the size of equivalent baseline machine code
- combines cutting-edge IR (intermediate representation) with multi-layered translation + optimization pipeline
- relaxed sea of nodes approach allows more effective reordering and optimization when generating CFG
- to achieve that fluid code motion, control flow optimizations and precise numerical range analysis are used
- clearer separation between JavaScript, V8 and the target architectures allows cleaner, more robust generated code and adds flexibility
- generates better quality machine code than Crankshaft JIT
- crossing from JS to C++ land has been minimized using techniques like CodeStubAssembler
- as a result optimizations can be applied in more cases and are attempted more aggressively
- for the same reason (and due to other improvements) TurboFan inlines code more aggressively, leading to even more performance improvements
- for most websites the optimizing compiler isn't important and could even hurt performance (speculative optimizations aren't cheap)
- pages need to load fast and unoptimized code needs to run fast enough, esp. on mobile devices
- previous V8 implementations suffered from performance cliffs
- optimized code ran super fast (focus on peak performance case)
- baseline performance was much lower
- as a result one feature in your code that prevented it's optimization would affect your app's performance dramatically, i.e. 100x difference
- TurboFan improves this as
- widens fast path to ensure that optimized code is more flexible and can accept more types of arguments
- reduces code memory overhead by reusing code generation parts of TurboFan to build Ignition interpreter
- improves slow path
- bytecode smaller and faster to generate than machine code (crankshaft)
- bytecode better suited for smaller icache (low end mobile)
- code parsed + AST converted to bytecode only once and optimized from bytecode
- data driven ICs reduced slow path cost (collected in feedback form, previously collected in code form)
- most important on mobile
- Ignition code up to 8x smaller than Full-Codegen code (crankshaft)
- no longer relying on optimizing compiler for sufficiently fast code
- thus improved baseline performance allows delaying optimization until more feedback is collected
- avoids optimizations of infrequently executed code
- leads to less time and resources spent optimizing
- can address optimization killers that Crankshaft couldn't b/c it never supported fundamental techniques needed to do so
- as a result no specific syntax (like
try/catch) inside a function will cause it not being optimized - other subtle optimization killers that made performance unpredictable are no longer an issue and if they are they can be easily fixed in TF
- passing
undefinedas first parameter toMath.max.apply - mixing strict and sloppy modes
- passing
- easier to support future JavaScript features as the JavaScript frontend is clearly separated from the architecture dependent backends
- new language features are not useful by just being implemented
- need to be fast (at least matching transpiled code), related optimizations are easier with new pipeline
- need to support debugging and be inspectable, this is achieved via better integration with Chrome DevTools
- new language features are easier optimized which makes them useable after much shorter time after they are introduced to V8 (previously performance issues for new features prevented their use in code that needed to run fast)
- performance of ES6 features relative to the ES5 baseline operations per second tracked at sixspeed
- at this point ES6 features are almost on par with ES5 versions of same code for most cases
watch how to leverage babel optimally| read deploying es2015 code
- using features directly, instead of transpiling, results in smaller code size watch
- additionally less parse time for untranspiled code and easier optimized
- use babel-preset-env to specify browsers to target
- therefore transpile es2015+ selectively
- uses TurboFan's low-level architecture-independent macro-assembly instructions to generate bytecode handlers for each opcode
- TurboFan compiles these instructions to target architecture including low-level instruction selection and machine register allocation
- bytecode passes through inline-optimization stages as it is generated
- common patterns replaced with faster sequences
- redundant operations removed
- minimize number of register transfers
- this results in highly optimized and small interpreter code which can execute the bytecode instructions and interact with rest of V8 VM in low overhead manner
- Ignition Interpreter uses a register machine with each bytecode specifying inputs and outputs as explicit register operands
- holds its local state in interpreter registers
- some map to real CPU registers
- others map to specific slots in native machine stack memory
- last computed value of each bytecode is kept in special accumulator register minimizing load/store operations (from/to explicit registers)
- current stack frame is identified by stack pointer
- program counter points to currently executed instruction in the bytecode
- each bytecode handler tail-calls into the next bytecode handler (indirectly threaded interpreter)
watch hidden classes/maps | watch | watch feedback workflow
Inline Caches implemented in JavaScript
- gather knowledge about types while program runs
- feedback collected via data-driven approach
- uses FeedbackVector attached to every function, responsible to record and manage all execution feedback to later speed up its execution
- FeedbackVector linked from function closure and contains slots to store different kinds of feedback
- we can inspect what's inside the FeedbackVector of a function in a debug build of d8 by
passing the
--allow-natives-syntaxflag and calling%DebugPrint(fn) - if monomorphic compare maps and if they match just load prop at offset in memory, i.e.
mov eax, [eax+0xb] - IC feedback slots reserved when AST is created, see them via
--print-ast, i.e.Slot(0) at 29 - collect typeinfo for ~24% of the function's ICs before attempting optimization
- feedback vectors aren't embedded in optimized code but map ids or specific type checks, like for Smis
- see optimization + IC info via
--trace-opt - evaluate ICs via the
--trace-icflag
- operations are monomorphic if hidden classes of arguments are always same
- all others are polymorphic at best and megamorphic at worst
- polymorphic: 2-4 different types seen
- monomorphic operations are easier optimized
- the feedback lattice describes the possible states of feedback that can be collected about the type of a function argument
- all states but Any are considered monomorphic and Any is considered polymorphic
- states can only change in one direction, thus going back from Number to SignedSmall is not possible for instance

+-------------+
| Closure |-------+-------------------+--------------------+
+-------------+ | | |
↓ ↓ ↓
+-------------+ +--------------------+ +-----------------+
| Context | | SharedFunctionInfo | | Feedback Vector |
+-------------+ +--------------------+ +-----------------+
| | Invocation Count|
| +-----------------+
| | Optimized Code |
| +-----------------+
| | Binary Op |
| +-----------------+
|
| +-----------------+
+-----------> | Byte Code |
+-----------------+
- function Closure links to Context, SharedFunctionInfo and FeedbackVector
- Context: contains values for the free variables of the function
and provides access to global object
- free variables are variables that are neither local nor paramaters to the function, i.e. they are in scope of the function but declared outside of it
- SharedFunctionInfo: general info about the function like source position and bytecode
- FeedbackVector: collects feedback via ICs as explained above
watch TurboFan history | watch TurboFan goals
TurboFan is a simple compiler + backend responsible for the following:
- instruction selection + scheduling
- innovative scheduling algorithm makes use of reordering freedom (sea of nodes) to move code out of loops into less frequently executed paths
- register allocation
- code generation
- generates fast code via speculative optimization from the feedback collected while running unoptimized bytecode
- architecture specific optimizations exploit features of each target platform for best quality code
TurboFan is not just an optimizing compiler:
- interpreter bytecode handlers run on top of TurboFan
- builtins benefit from TurboFan
- code stubs / IC subsystem runs on top of TurboFan
- web assembly code generation (also runs on top of TurboFan by using its back-end passes)
- recompiles and optimizes hot code identified by the runtime profiler
- compiler speculates that kinds of values seen in the past will be see in the future as well
- generates optimized code just for those cases which is not only smaller but also executes at peak speed
Bytecode Interpreter State Machine Stack
+--------------+ +-------------------+ +--------------+
| StackCheck | <----+ | stack pointer |---+ | receiver |
+--------------+ | +-------------------+ | +--------------+
| Ldar a1 | +-- | program counter | | | a0 |
+--------------+ +-------------------+ | +--------------+
| Add a0, [0] | | accumulator | | | a1 |
+--------------+ +-------------------+ | +--------------+
| Return | | | return addr. |
+--------------+ | +--------------+
| | context |
| +--------------+
| | closure |
| +--------------+
+---> | frame pointer|
+--------------+
| ... |
+--------------+
StackCheck ; check for stack overflow
Ldar a1 ; load a1 into accumulator register
Add a0, [0] ; load value from a0 register and add it to value in accumulator register
Return ; end execution, return value in accum. reg. and tranfer control to caller- the
[0]ofAdd a0, [0]refers to feedback vector slot where Ignition stores profiling info which later is used by TurboFan to optimize the function +operator needs to perform a huge amount of checks to cover all cases, but if we assume that we always add numbers we don't have to handle those other cases- additionally numbers don't call side effects and thus the compiler knows that it can eliminate the expression as part of the optimization
- optimizations are speculative and assumptions are made
- if assumption is violated
- function deoptimized
- execution resumes in Ignition bytecode
- in short term execution slows down
- normal to occur
- more info about about function collected
- better optimization attempted
- if assumptions are violated again, deoptimized again and start over
- too many deoptimizations cause function to be sent to deoptimization hell
- considered not optimizable and no optimization is ever attempted again
- assumptions are verified as follows:
- code objects are verified via a
testin the prologue of the generated machine code for a particular function - argument types are verified before entering the function body
- code objects are verified via a
watch bailout example | watch walk through TurboFan optimized code with bailouts
- when assumptions made by optimizing compiler don't hold it bails out to deoptimized code
- on bail out the code object is thrown away as it doesn't handle the current case
- trampoline to unoptimized code (stored in SharedFunctionInfo) used to jump and continue execution
; x64 machine code generated by TurboFan for the Add Example above
; expecting that both parameters and the result are Smis
leaq rcx, [rip+0x0] ; load memory address of instruction pointer into rcx
movq rcx, [rcx-0x37] ; copy code object stored right in front into rcx
testb [rcx+0xf], 0x1 ; check if code object is valid
jnz CompileLazyDeoptimizedCode ; if not bail out via a jump
[ .. ] ; push registers onto stack
cmpq rsp, [r13+0xdb0] ; enough space on stack to execute code?
jna StackCheck ; if not we're sad and raise stack overflow
movq rax, [rbp+0x18] ; load x into rax
test al, 0x1 ; check tag bit to ensure x is small integer
jnz Deoptimize ; if not bail
movq rbx, [rbp+0x10] ; load y into rbx
testb rbx, 0x1 ; check tag bit to ensure y is small integer
jnz Deoptimize ; if not bail
[ .. ] ; do some nifty conversions via shifts
; and store results in rdx and rcx
addl rdx, rcx ; perform add including overflow check
jo Deoptimize ; if overflowed bail
[ .. ] ; cleanup and return to caller- code objects created during optimization are no longer useful after deoptimization
- on deoptimization embedded fields of code object are invalidated, however code object itself is kept alive
- for performance reasons unlinking of code object is postponed until next invocation of the function in question
- occurred when optimized code deoptimized and there was no way to learn what went wrong
- one cause was altering the shape of the array in the callback function of a second order array builtin, i.e. by changing it's length
- TurboFan kept trying to optimized and gave up after ~30 attempts
- starting with V8 v6.5 this is detected and array built in is no longer inlined at that site on future optimization attempts
- added fields (order matters) to object generate id of hidden class
- adding more fields later on generates new class id which results in code using Point that now gets Point' to be deoptimized
function Point(x, y) {
this.x = x;
this.y = y;
}
var p = new Point(1, 2); // => hidden Point class created
// ....
p.z = 3; // => another hidden class (Point') createdPointclass created, code still deoptimized- functions that have
Pointargument are optimized zproperty added which causesPoint'class to be created- functions that get passed
Point'but were optimized forPointget deoptimized - later functions get optimized again, this time supporting
PointandPoint'as argument - detailed explanation
- avoid hidden class changes
- initialize all members in the class constructor or the prototype constructor function
and in the same order
- this creates one place in your code base where properties are assigned to an Object
- you may use Object literals, i.e.
const a = {}orconst a = { b: 1 }, as they also benefit from hidden classes, but the creation of those may be spread around your code base and it becomes much harder to verify that you are assigning the same properties in the same order
function createPoint(x, y) {
class Point {
constructor(x, y) {
this.x = x
this.y = y
}
distance(other) {
const dx = Math.abs(this.x - other.x)
const dy = Math.abs(this.y - other.y)
return dx + dy
}
}
return new Point(x, y)
}
function usePoint(point) {
// do something with the point
}- defining a class inside
createPointresults in its definition to be executed on eachcreatePointinvocation - executing that definition causes a new prototype to be created along with methods and constructor
- thus each new point has a different prototype and thus a different object shape
- passing these objects with differing prototypes to
usePointmakes that function become polymorphic - V8 gives up on polymorphism after it has seen more than 4 different object shapes, and enters megamorphic state
- as a result
usePointwon't be optimized - pulling the
Pointclass definition out of thecreatePointfunction fixes that issue as now the class definition is only executed once and all point prototypes match - the performance improvement resulting from this simple change is substantial, the exact
speedup factor depends on the
usePointfunction - when class or prototype definition is collected it's hidden class (associated maps) are collected as well
- need to re-learn hidden classes for short living objects including metadata and all feedback collected by inline caches
- references to maps and JS objects from optimized code are considered weak to avoid memory leaks
- always declare classes at the script scope, i.e. never inside functions when it is avoidable
- smart heuristics, i.e. how many times was the function called so far
- part of the compilation pipeline that doesn't acess objects on the JavaScript heap run on a background thread
- via some optimization to the bytecode compiler and how AST is stored and accessed, almost all of the compilation of a script happens on a background thread
- only short AST internalizatoin and bytecode finalization happens on main thread
- doesn't include total order of program, but control dependencies between operations
- instead expresses many possible legal orderings of code
- most efficient ordering and placement can be derived from the nodes
- depends on control dominance, loop nesting, register pressure
- graph reductions applied to further optimize
- total ordering (traditional CFG) is built from that, so code can be generated and registers allocated
- entrypoints are TurboFan optimizing compiler and WASM Compiler
Flexibility of sea of nodes approach enables the below optimizations.
- better redundant code elimination due to more code motion
- loop peeling
- load/check elimination
- escape analysis watch | watch
- eliminates non-escaping allocations
- aggregates like
const o = { foo: 1, bar: 2}are replaces with scalars likeconst o_foo = 1; const o_bar = 2
- representation selection
- optimizing of number representation via type and range analysis
- slides
- redundant store elimination
- control flow elimination
- turns branch chains into switches
- allocation folding and write barrier elimination
- verify var is only assigned once (SSA - single static assignment)
- compiler may move the assignment anywhere, i.e. outside a loop
- may remove redundant checks
watch | read | slides | slides
- defines a portable assembly language built on top of TurboFan's backend and adds a C++ based API to generate highly portable TurboFan machine-level IR directly
- can generate highly efficient code for parts of slow-paths in JS without crossing to C++ runtime
- API includes very low-level operations (pretty much assembly), primitive CSA instructions that translate directly into one or two assembly instructions
- Macros include fixed set of pre-defined CSA instructions corresponding to most commonly used assembly instructions

The CSA allows much faster iteration when implementing and optimizing new language features due to the following characteristics.
- CSA includes type verification at IR level to catch many correctness bugs at compile time
- CSA's instruction selector ensures that optimal code is generated on all platforms
- CSA's performs register allocations automatically
- CSA understands API calling conventions, both standard C++ and internal V8 register-based, i.e. entry-point stubs into C++ can easily be called from CSA, making trivial to interoperate between CSA generated code and other parts of V8
- CSA-based built in functionality can easily be inlined into Ignition bytecode handlers to improve its performance
- builtins are coded in that DSL (no longer self hosted)
- very fast property accesses
CSA is the basis for fast builtins and thus was used to speed up multiple builtins. Below are a few examples.
- faster Regular Expressions sped up by removing need to switch between C++ and JavaScript runtimes
Object.createhas predictable performance by using CodeStubAssemblerFunction.prototype.bindachieved final boost when ported to CodeStubAssembler for a total 60,000% improvementPromises where ported to CodeStubAssembler which resulted in 500% speedup forasync/await
- performance of your code is improved
- less anti patterns aka you are holding it wrong
- write idiomatic, declarative JavaScript as in easy to read JavaScript with good data structures and algorithms, including all language features (even functional ones) will execute with predictable, good performance
- instead focus on your application design
- now can handle exceptions where it makes sense as
try/catch/finallyno longer ruins the performance of a function - use appropriate collections as their performance is on par with the raw use of Objects for same task
- Maps, Sets, WeakMaps, WeakSets used where it makes sense results in easier maintainable JavaScript as they offer specific functionality to iterate over and inspect their values
- avoid engine specific workarounds aka CrankshaftScript, instead file a bug report if you discover a bottleneck
- V8: Behind the Scenes (November Edition) - 2016
- V8: Behind the Scenes (February Edition - 2017)
- An Introduction to Speculative Optimization in V8 - 2017
- High-performance ES2015 and beyond - 2017
- Launching Ignition and TurboFan - 2017
- lazy unlinking of deoptimized functions - 2017
- Taming architecture complexity in V8 — the CodeStubAssembler - 2017
- V8 release v6.5 - 2018
- Background compilation - 2018
- Sea of Nodes - 2015
- CodeStubAssembler: Redux - 2016
- Deoptimization in V8 - 2016
- Turbofan IR - 2016
- TurboFan: A new code generation architecture for V8 - 2017
- Fast arithmetic for dynamic languages - 2016
- An overview of the TurboFan compiler - 2016
- TurboFan JIT Design - 2016